一、入门
《Java 2从入门到精通》- 推荐
《Thinking in Java》- 强烈推荐*
O’reilly的Java编程基础系列 - 参考*
二、进阶
《Java Cook Book》- 非常推荐* (包含了Java编程的Tips,适合当做手册来查阅)
《O’reilly-Java IO》- 推荐* (包含Java IO编程的各个方面)
《O’reilly-Database Programming with JDBC》- 推荐* (JDBC编程)
《O’reilly-Java Programming with Oracle JDBC》- 参考*
三、Java Web编程
《O’reilly-Java Server Pages》- 强烈推荐*
《O’reilly-Java Servlet Programming》- 非常推荐*
《O’reilly-Jakarta Struts》- 推荐* (Java Web编程的一个MVC实现框架Struts的书)
四、EJB编程
《J2EE应用与BEA Weblogic Server》- 强烈推荐
《Mastering EJB 2.0》- 非常推荐*
《Enterprise Java Bean》- 推荐*
五、Java XML编程
《O’reilly-Java and XML》- 推荐*
《O’reilly-Java and SOAP》- 参考* (Java的SOAP编程)
六、设计模式
《Core J2EE Patterns》- 强烈推荐* (J2EE设计模式,设计企业应用软件必备参考书)
《EJB Design Patterns》- 推荐*
七、其它
《O’reilly Ant - The Definitive Guide》- 推荐* (Ant是一种功能非常强大的Java工具)
Note:
强烈推荐书籍:建议购买,重点学习
非常推荐书籍:建议花时间学习
推荐书籍:在学有余力的情况下,建议学习
参考书籍:有兴趣的情况下学习
标明*号的书籍有电子版本
可以去http://www.china-pub.com 看看
12.07.2008
Java书籍
学习Java之路
http://news.csdn.net/n/20070416/102870.html
JAVA是一种平台,也是一种程序设计语言,如何学好程序设计不仅仅适用于JAVA,对C++等其他程序设计语言也一样管用。有编程高手认为,JAVA也 好C也好没什么分别,拿来就用。为什么他们能达到如此境界?我想是因为编程语言之间有共通之处,领会了编程的精髓,自然能够做到一通百通。如何学习程序设 计理所当然也有许多共通的地方。
1.1 培养兴趣
兴趣是能够让你坚持下去的动力。如果只是把写程序作为谋生的手段的话,你会活的很累,也太对不起自己了。多关心一些行业趣事,多想想盖茨。不是提倡天 天做白日梦,但人要是没有了梦想,你觉得有味道吗?可能像许多深圳本地农民一样,打打麻将,喝喝功夫茶,拜拜财神爷;每个月就有几万十几万甚至更多的进 帐,凭空多出个"食利阶层"。你认为,这样有味道吗?有空多到一些程序员论坛转转,你会发现,他们其实很乐观幽默,时不时会冒出智慧的火花。
1.2 慎选程序设计语言
男怕入错行,女怕嫁错郎。初学者选择程序设计语言需要谨慎对待。软件开发不仅仅是掌握一门编程语言了事,它还需要其他很多方面的背景知识。软件开发也不仅仅局限于某几个领域,而是已经渗透到了各行各业几乎每一个角落。
如果你对硬件比较感兴趣,你可以学习C语言/汇编语言,进入硬件开发领域。如果你对电信的行业知识及网络比较熟悉,你可以在C/C++等之上多花时 间,以期进入电信软件开发领域。如果你对操作系统比较熟悉,你可以学习C/Linux等等,为Linux内核开发/驱动程序开发/嵌入式开发打基础。如果 你想介入到应用范围最广泛的应用软件开发(包括电子商务电子政务系统)的话,你可以选择J2EE或.NET,甚至LAMP组合。每个领域要求的背景知识不 一样。做应用软件需要对数据库等很熟悉。总之,你需要根据自己的特点来选择合适你的编程语言。
1.3 要脚踏实地,快餐式的学习不可取
先分享一个故事。
有一个小朋友,他很喜欢研究生物学,很想知道那些蝴蝶如何从蛹壳里出来,变成蝴蝶便会飞。 有一次,他走到草原上面看见一个蛹,便取了回家,然后看着,过了几天以后,这个蛹出了一条裂痕,看见里面的蝴蝶开始挣扎,想抓破蛹壳飞出来。 这个过程达数小时之久,蝴蝶在蛹里面很辛苦地拼命挣扎,怎么也没法子走出来。这个小孩看着看着不忍心,就想不如让我帮帮它吧,便随手拿起剪刀在蛹上剪开, 使蝴蝶破蛹而出。 但蝴蝶出来以后,因为翅膀不够力,变得很臃肿,飞不起来。
这个故事给我们的启示是:欲速则不达。
浮躁是现代人最普遍的心态,能怪谁?也许是贫穷落后了这么多年的缘故,就像当年的大跃进一样,都想大步跨入共产主义社会。现在的软件公司、客户、政 府、学校、培训机构等等到处弥漫着浮躁之气。就拿笔者比较熟悉的深圳IT培训行业来说吧,居然有的打广告宣称"参加培训,100%就业",居然报名的学生 不少,简直是藐视天下程序员。社会环境如是,我们不能改变,只能改变自己,闹市中的安宁,弥足珍贵。许多初学者C++/JAVA没开始学,立马使用VC /JBuilder,会使用VC/JBuilder开发一个Hello World程序,就忙不迭的向世界宣告,"我会软件开发了",简历上也大言不惭地写上"精通VC/JAVA"。结果到软件公司面试时要么被三两下打发走 了,要么被驳的体无完肤,无地自容。到处碰壁之后才知道捧起《C++编程思想》《JAVA编程思想》仔细钻研,早知如此何必当初呀。
"你现在讲究简单方便,你以后的路就长了",好象也是佛经中的劝戒。
1.4 多实践,快实践
彭端淑的《为学一首示子侄》中有穷和尚与富和尚的故事。
从前,四川边境有两个和尚,一个贫穷,一个有钱。一天,穷和尚对富和尚说:"我打算去南海朝圣,你看怎么样?"富和尚说:"这里离南海有几千里远,你 靠什么去呢?"穷和尚说:"我只要一个水钵,一个饭碗就够了。"富和尚为难地说:"几年前我就打算买条船去南海,可至今没去成,你还是别去吧!" 一年以后,富和尚还在为租赁船只筹钱,穷和尚却已经从南海朝圣回来了。
这个故事可解读为:任何事情,一旦考虑好了,就要马上上路,不要等到准备周全之后,再去干事情。假如事情准备考虑周全了再上路的话,别人恐怕捷足先登 了。软件开发是一门工程学科,注重的就是实践,"君子动口不动手"对软件开发人员来讲根本就是错误的,他们提倡"动手至上",但别害怕,他们大多温文尔 雅,没有暴力倾向,虽然有时候蓬头垢面的一副"比尔盖茨"样。有前辈高人认为,学习编程的秘诀是:编程、编程、再编程,笔者深表赞同。不仅要多实践,而且 要快实践。我们在看书的时候,不要等到你完全理解了才动手敲代码,而是应该在看书的同时敲代码,程序运行的各种情况可以让你更快更牢固的掌握知识点。
1.5 多参考程序代码
程序代码是软件开发最重要的成果之一,其中渗透了程序员的思想与灵魂。许多人被《仙剑奇侠传》中凄美的爱情故事感动,悲剧的结局更有一种缺憾美。为什 么要以悲剧结尾?据说是因为写《仙剑奇侠传》的程序员失恋而安排了这样的结局,他把自己的感觉融入到游戏中,却让众多的仙剑迷扼腕叹息。
多多参考代码例子,对JAVA而言有参考文献[4.3],有API类的源代码(JDK安装目录下的src.zip文件),也可以研究一些开源的软件或框架。
1.6 加强英文阅读能力
对学习编程来说,不要求英语, 但不能一点不会,。最起码像JAVA API文档(参考文献[4.4])这些东西还是要能看懂的,连猜带懵都可以;旁边再开启一个"金山词霸"。看多了就会越来越熟练。在学JAVA的同时学习 英文,一箭双雕多好。另外好多软件需要到英文网站下载,你要能够找到它们,这些是最基本的要求。英语好对你学习有很大的帮助。口语好的话更有机会进入管理 层,进而可以成为剥削程序员的"周扒皮"。
1.7 万不得已才请教别人
笔者在ChinaITLab网校的在线辅导系统中解决学生问题时发现,大部分的问题学生稍做思考就可以解决。请教别人之前,你应该先回答如下几个问题。
你是否在google中搜索了问题的解决办法?
你是否查看了JAVA API文档?
你是否查找过相关书籍?
你是否写代码测试过?
如果回答都是"是"的话,而且还没有找到解决办法,再问别人不迟。要知道独立思考的能力对你很重要。要知道程序员的时间是很宝贵的。
1.8 多读好书
书中自有颜如玉。比尔?盖茨是一个饱读群书的人。虽然没有读完大学,但九岁的时候比尔?盖茨就已经读完了所有的百科全书,所以他精通天文、历史、地理等等各类学科,可以说比尔?盖茨不仅是当今世界上金钱的首富,而且也可以称得上是知识的巨富。
笔者在给学生上课的时候经常会给他们推荐书籍,到后来学生实在忍无可忍开始抱怨,"天呐,这么多书到什么时候才能看完了","学软件开发,感觉上了贼 船"。这时候,我的回答一般是,"别着急,什么时候带你们去看看我的书房,到现在每月花在技术书籍上的钱400元,这在软件开发人员之中还只能够算是中等 的",学生当场晕倒。(注:这一部分学生是刚学软件开发的)
对于在JAVA开发领域的好书在笔者另外一篇文章中会专门点评。该文章可作为本文的姊妹篇。
1.9 使用合适的工具
工欲善其事必先利其器。软件开发包含各种各样的活动,需求收集分析、建立用例模型、建立分析设计模型、编程实现、调试程序、自动化测试、持续集成等 等,没有工具帮忙可以说是寸步难行。工具可以提高开发效率,使软件的质量更高BUG更少。组合称手的武器。到飞花摘叶皆可伤人的境界就很高了,无招胜有 招,手中无剑心中有剑这样的境界几乎不可企及。在笔者另外一篇文章中会专门阐述如何选择合适的工具(该文章也可作为本文的姊妹篇)。
2.软件开发学习路线
两千多年的儒家思想孔孟之道,中庸的思想透入骨髓,既不冒进也不保守并非中庸之道,而是找寻学习软件开发的正确路线与规律。
从软件开发人员的生涯规划来讲,我们可以大致分为三个阶段,软件工程师→软件设计师→架构设计师或项目管理师。不想当元帅的士兵不是好士兵,不想当架 构设计师或项目管理师的程序员也不是好的程序员。我们应该努力往上走。让我们先整理一下开发应用软件需要学习的主要技术。
A.基础理论知识,如操作系统、编译原理、数据结构与算法、计算机原理等,它们并非不重要。如不想成为计算机科学家的话,可以采取"用到的时候再来学"的原则。
B.一门编程语言,现在基本上都是面向对象的语言,JAVA/C++/C#等等。如果做WEB开发的话还要学习HTML/JavaScript等等。
C.一种方法学或者说思想,现在基本都是面向对象思想(OOA/OOD/设计模式)。由此而衍生的基于组件开发CBD/面向方面编程AOP等等。
D.一种关系型数据库,ORACLE/SqlServer/DB2/MySQL等等
E.一种提高生产率的IDE集成开发环境JBuilder/Eclipse/VS.NET等。
F.一种UML建模工具,用ROSE/VISIO/钢笔进行建模。
G.一种软件过程,RUP/XP/CMM等等,通过软件过程来组织软件开发的众多活动,使开发流程专业化规范化。当然还有其他的一些软件工程知识。
H.项目管理、体系结构、框架知识。
正确的路线应该是:B→C→E→F→G→H。
还需要补充几点:
1).对于A与C要补充的是,我们应该在实践中逐步领悟编程理论与编程思想。新技术虽然不断涌现,更新速度令人眼花燎乱雾里看花;但万变不离其宗,编 程理论与编程思想的变化却很慢。掌握了编程理论与编程思想你就会有拨云见日之感。面向对象的思想在目前来讲是相当关键的,是强势技术之一,在上面需要多投 入时间,给你的回报也会让你惊喜。
2).对于数据库来说是独立学习的,这个时机就由你来决定吧。
3).编程语言作为学习软件开发的主线,而其余的作为辅线。
4).软件工程师着重于B、C、E、 D;软件设计师着重于B、C、E、 D、F;架构设计师着重于C、F、H。
3.如何学习JAVA?
3.1 JAVA学习路线
3.1.1 基础语法及JAVA原理
基础语法和JAVA原理是地基,地基不牢靠,犹如沙地上建摩天大厦,是相当危险的。学习JAVA也是如此,必须要有扎实的基础,你才能在J2EE、 J2ME领域游刃有余。参加SCJP(SUN公司认证的JAVA程序员)考试不失为一个好方法,原因之一是为了对得起你交的1200大洋考试费,你会更努 力学习,原因之二是SCJP考试能够让你把基础打得很牢靠,它要求你跟JDK一样熟悉JAVA基础知识;但是你千万不要认为考过了SCJP就有多了不起, 就能够获得软件公司的青睐,就能够获取高薪,这样的想法也是很危险的。获得"真正"的SCJP只能证明你的基础还过得去,但离实际开发还有很长的一段路要 走。
3.1.2 OO思想的领悟
掌握了基础语法和JAVA程序运行原理后,我们就可以用JAVA语言实现面向对象的思想了。面向对象,是一种方法学;是独立于语言之外的编程思想;是 CBD基于组件开发的基础;属于强势技术之一。当以后因工作需要转到别的面向对象语言的时候,你会感到特别的熟悉亲切,学起来像喝凉水这么简单。
使用面向对象的思想进行开发的基本过程是:
●调查收集需求。
●建立用例模型。
●从用例模型中识别分析类及类与类之间的静态动态关系,从而建立分析模型。
●细化分析模型到设计模型。
●用具体的技术去实现。
●测试、部署、总结。
3.1.3 基本API的学习
进行软件开发的时候,并不是什么功能都需要我们去实现,也就是经典名言所说的"不需要重新发明轮子"。我们可以利用现成的类、组件、框架来搭建我们的 应用,如SUN公司编写好了众多类实现一些底层功能,以及我们下载过来的JAR文件中包含的类,我们可以调用类中的方法来完成某些功能或继承它。那么这些 类中究竟提供了哪些方法给我们使用?方法的参数个数及类型是?类的构造器需不需要参数?总不可能SUN公司的工程师打国际长途甚至飘洋过海来告诉你他编写 的类该如何使用吧。他们只能提供文档给我们查看,JAVA DOC文档(参考文献4.4)就是这样的文档,它可以说是程序员与程序员交流的文档。
基本API指的是实现了一些底层功能的类,通用性较强的API,如字符串处理/输入输出等等。我们又把它成为类库。熟悉API的方法一是多查JAVA DOC文档(参考文献4.4),二是使用JBuilder/Eclipse等IDE的代码提示功能。
3.1.4 特定API的学习
JAVA介入的领域很广泛,不同的领域有不同的API,没有人熟悉所有的API,对一般人而言只是熟悉工作中要用到的API。如果你做界面开发,那么 你需要学习Swing/AWT/SWT等API;如果你进行网络游戏开发,你需要深入了解网络API/多媒体API/2D3D等;如果你做WEB开发,就 需要熟悉Servlet等API啦。总之,需要根据工作的需要或你的兴趣发展方向去选择学习特定的API。
3.1.5 开发工具的用法
在学习基础语法与基本的面向对象概念时,从锻炼语言熟练程度的角度考虑,我们推荐使用的工具是Editplus/JCreator+JDK,这时候不 要急于上手JBuilder/Eclipse等集成开发环境,以免过于关注IDE的强大功能而分散对JAVA技术本身的注意力。过了这一阶段你就可以开始 熟悉IDE了。
程序员日常工作包括很多活动,编辑、编译及构建、调试、单元测试、版本控制、维持模型与代码同步、文档的更新等等,几乎每一项活动都有专门的工具,如 果独立使用这些工具的话,你将会很痛苦,你需要在堆满工具的任务栏上不断的切换,效率很低下,也很容易出错。在JBuilder、Eclipse等IDE 中已经自动集成编辑器、编译器、调试器、单元测试工具JUnit、自动构建工具ANT、版本控制工具CVS、DOC文档生成与更新等等,甚至可以把UML 建模工具也集成进去,又提供了丰富的向导帮助生成框架代码,让我们的开发变得更轻松。应该说IDE发展的趋势就是集成软件开发中要用到的几乎所有工具。
从开发效率的角度考虑,使用IDE是必经之路,也是从一个学生到一个职业程序员转变的里程碑。
JAVA开发使用的IDE主要有Eclipse、JBuilder、JDeveloper、NetBeans等几种;而Eclipse、 JBuilder占有的市场份额是最大的。JBuilder在近几年来一直是JAVA集成开发环境中的霸主,它是由备受程序员尊敬的Borland公司开 发,在硝烟弥漫的JAVA IDE大战中,以其快速的版本更新击败IBM的Visual Age for JAVA等而成就一番伟业。IBM在Visual Age for JAVA上已经无利可图之下,干脆将之贡献给开源社区,成为Eclipse的前身,真所谓"柳暗花明又一村"。浴火重生的Eclipse以其开放式的插件 扩展机制、免费开源获得广大程序员(包括几乎所有的骨灰级程序员)的青睐,极具发展潜力。
3.1.6 学习软件工程
对小型项目而言,你可能认为软件工程没太大的必要。随着项目的复杂性越来越高,软件工程的必要性才会体现出来。参见"软件开发学习路线"小节。
3.2学习要点
确立的学习路线之后,我们还需要总结一下JAVA的学习要点,这些要点在前文多多少少提到过,只是笔者觉得这些地方特别要注意才对它们进行汇总,不要嫌我婆婆妈妈啊。
3.2.1勤查API文档
当程序员编写好某些类,觉得很有成就感,想把它贡献给各位苦难的同行。这时候你要使用"javadoc"工具(包含在JDK中)生成标准的JAVA DOC文档,供同行使用。J2SE/J2EE/J2ME的DOC文档是程序员与程序员交流的工具,几乎人手一份,除了菜鸟之外。J2SE DOC文档官方下载地址:http://java.sun.com/j2se/1.5.0/download.jsp,你可以到google搜索CHM版 本下载。也可以在线查看:http://java.sun.com/j2se/1.5.0/docs/api/index.html。
对待DOC文档要像毛主席语录,早上起床念一遍,吃饭睡觉前念一遍。
当需要某项功能的时候,你应该先查相应的DOC文档看看有没有现成的实现,有的话就不必劳神费心了直接用就可以了,找不到的时候才考虑自己实现。使用步骤一般如下:
●找特定的包,包一般根据功能组织。
●找需要使用类,类命名规范的话我们由类的名字可猜出一二。
●选择构造器,大多数使用类的方式是创建对象。
●选择你需要的方法。
3.2.2 查书/google->写代码测试->查看源代码->请教别人
当我们遇到问题的时候该如何解决?
这时候不要急着问别人,太简单的问题,没经过思考的问题,别人会因此而瞧不起你。可以先找找书,到google中搜一下看看,绝大部分问题基本就解决 了。而像"某些类/方法如何使用的问题",DOC文档就是答案。对某些知识点有疑惑是,写代码测试一下,会给你留下深刻的印象。而有的问题,你可能需要直 接看API的源代码验证你的想法。万不得已才去请教别人。
3.2.3学习开源软件的设计思想
JAVA领域有许多源代码开放的工具、组件、框架,JUnit、ANT、Tomcat、Struts、Spring、Jive论坛、PetStore 宠物店等等多如牛毛。这些可是前辈给我们留下的瑰宝呀。入宝山而空手归,你心甘吗?对这些工具、框架进行分析,领会其中的设计思想,有朝一日说不定你也能 写一个XXX框架什么的,风光一把。分析开源软件其实是你提高技术、提高实战能力的便捷方法。
3.2.4 规范的重要性
没有规矩,不成方圆。这里的规范有两层含义。第一层含义是技术规范,多到http://www.jcp.org下载JSRXXX规范,多读规范,这是 最权威准确最新的教材。第二层含义是编程规范,如果你使用了大量的独特算法,富有个性的变量及方法的命名方式;同时,没给程序作注释,以显示你的编程功底 是多么的深厚。这样的代码别人看起来像天书,要理解谈何容易,更不用说维护了,必然会被无情地扫入垃圾堆。JAVA编码规范到此查看或下载 http://java.sun.com/docs/codeconv/,中文的也有,啊,还要问我在哪,请参考3.2.2节。
3.2.5 不局限于JAVA
很不幸,很幸运,要学习的东西还有很多。不幸的是因为要学的东西太多且多变,没时间陪老婆家人或女朋友,导致身心疲惫,严重者甚至导致抑郁症。幸运的是别人要抢你饭碗绝非易事,他们或她们需要付出很多才能达成心愿。
JAVA不要孤立地去学习,需要综合学习数据结构、OOP、软件工程、UML、网络编程、数据库技术等知识,用横向纵向的比较联想的方式去学习会更有 效。如学习JAVA集合的时候找数据结构的书看看;学JDBC的时候复习数据库技术;采取的依然是"需要的时候再学"的原则。
9.08.2008
制作PDF的软件和方法
我们知道很多种分割合并制作PDF的软件和方法。但我们还是推荐你使用这些最受欢迎的方法。这里推荐的工具和服务有些是免费版的,当然也有需要付费的。尽管如此,他们仍然比我们熟知的一些软件要便宜的多~
在线PDF转换

Adobe公司的 Create PDF Online 能够将包括网页在内的多种形式转换为 Adobe PDF。在网站上我们还可以做图像和文字的扫描识别。(在国内能做这个的真的不多~)
BCL Technology的 PDF Online 能够在人们最需要它的时候快速的生成PDF文件。作为他们的基本服务, 无论你身处哪里,家里,公司还是世界的任何角落,PDF Online 都能帮助你从PC, Mac,或者 Linux上生成PDF文件。
ESP的 PDF-o-matic运用简单的PHP脚本语言帮你完成转换。
Neevia 不需要安装任何软件,即可帮你直接完成由其他文件转换成 PDF或者是图像。
PDF4U 简单两步即可在线创建PDF文件。你可以上传到服务器在线转换,也可以下载免费的PDF4U Printer转换器.
Text2PDF是一个非常灵活又强有力的能转换文件,报告,表格到PDF的工具。具有多种语言选择,包括中,日,韩,徳,泰,希伯来等。
Loop Service 同样是一款基于网络的上传文件,转换为PDF的工具,不需安装任何软件。
Zamzar 在线转换,不需安装软件,支持多种格式转换,而且格式正在不断增加中。
您现在看到的文章来自于[布瓜堂-关注小事成就大事]我们关注方便实用的在线工具http://www.buguat.com
桌面转换
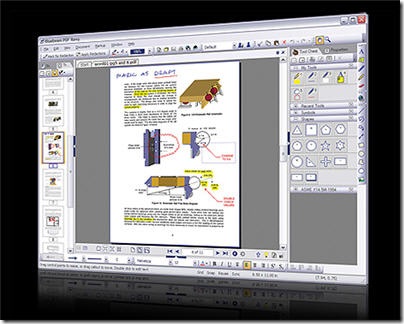
Ghostscript 是一个能提供与PDF和与其相关文件服务的软件. Ghostscript 是一系列相关软件的合称。
Softland的 doPDF对于个人和商业使用都是免费的。使用doPDF通过选择“打印”命令你可以创建具有搜索功能的PDF文件。轻轻点击,即可完成由Excel, Word或者是 PowerPoint,甚至是电子邮件和你喜欢的网站PDF的转换。
PDF995 能够轻松创建具有专业品质的PDF文件。界面亲和,点击“打印”即可直接完成多种格式的转换 ,还具有阅读器可以马上预览结果。 Pdf995支持网络文件的保存,共享打印,页面定制和大尺寸打印。
Google Docs——很知名吧?具有把文件保存成PDF的功能,同样通过简单的步骤即可完成共享。

ActivePDF的 PrimoPDF 通过PrimoPDF® printer几秒之内就可完成由 Word, Excel等多种格式到PDF的高质量转换。
MyPDFCreator 除了具有创建高质量PDF文件功能外,还具有安全管理和合并多个文件的功能。
CutePDF Writer 几乎能从打印方式支持所有文件格式到高质量PDF的转换。个人和商务使用都是绝对免费的。无水印,无广告,支持64位的 Windows.
PDF Creator 能够通过 Windows应用程序方便的创建文件。使用方式和Word, StarCalc的打印功能类似.
Global Graphics的 Jaws PDF Creator 提供了高质量的转换,及注释,合并等功能于一体。特别适合单用户,小公司办公和企业团体。
OpenOffice ——熟知的开源办公软件,同样具有转换PDF的功能。
Nuance的 PDF Converter需要付费,但是你一旦使用,就会发现你无法离开他了,因为许多功能实在是太棒了!(包括右键菜单中许多你想象不到的强大功能).
e-PDF Converter能够将 PDF反转为文件,表格,而且看上去和以前的一模一样。而且,它的费用是其他类似软件的 1/3。
Smart PDF Converter简单易用又功能强大。能将PDF转换为可编辑的Word,或者是HTML,TXT, XLS, JPEG, RTF, TIFF和其他格式的文件.
DocuDesk的 deskPDF 能创建100%兼容Adobe Acrobat的PDF文件。无论你是Microsoft Office用户,或者是 CAD的使用者,或者是什么其他300多款软件的使用者,deskPDF只需简单一步即可轻松完成PDF专业级的制作。
Bluebeam的 PDF Revu 对那些需要简单又智能的转换方案的用户来说可算是最理想的了. Bluebeam可以在Word, Excel 或者是PowerPoint的控制工具面板中田间控制按钮,所以转换步骤就会变得前所未有的简单 。而对于其他 Windows 软件(比若说WordPerfect, Outlook, image files来说.) Bluebeam提供了Bluebeam PDF Printer创建驱动,直接创建PDF ,还支持其他九种文件的转换,真的是十分简单啊.
Foxit Reader ——我们常用的PDF阅读器。自身同样具有编辑和创建的功能 .
Sowedoo的 EasyPDF Converter 能帮你在数秒内完成地图,建议书,报告,笔记到高质量安全的PDF文件的转换。而且你还可以通过互联网共享,或者通过电子邮件发送,而且毫无困难
您现在看到的文章来自于[布瓜堂-关注小事成就大事]我们关注方便实用的在线工具http://www.buguat.com
9.02.2008
LaTeX的代码样式
把自己总结的用了很久的一些LaTeX的代码样式发上来,这些样式平时用得很多。对我来说非常珍贵呀。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%一些最基本的环境
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%居中环境
\begin{center}
\end{center}
%左对齐环境
\begin{flushleft}
\end{flushleft}
%右对齐环境
\begin{flushright}
\end{flushright}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%小页环境(可嵌入上面那三种环境中形成组合)
\begin{minipage}{**cm}
\end{minipage}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%列举样式
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% itemize 列举样式1:· · · ·
\begin{itemize}
\vspace{-2.8mm}\item
\vspace{-2.8mm}\item
\end{itemize}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% itemize 列举样式2:* * * *
\begin{itemize}
\vspace{-2.8mm}\item[*]
\vspace{-2.8mm}\item[**]
\end{itemize}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% itemize 列举样式3:任意符号
\begin{itemize}
\renewcommand\labelitemi{}%这里面写符号
\vspace{-2.8mm}\item
\vspace{-2.8mm}\item
\end{itemize}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% itemize 列举样式4:彩色符号
\begin{itemize}
\setlength\baselineskip{12pt} %用这个命令来调整间距应该比较具有通用性
\item[\textcolor{black}{$\spadesuit$}] 文字。。。
\item[\textcolor{red}{$\heartsuit$}] 文字。。。
\item[\textcolor{black}{$\clubsuit$}] 文字。。。
\item[\textcolor{red}{$\diamondsuit$}] 文字。。。
\end{itemize}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% enumerate 列举样式1:1. 2. 3. 4.
\begin{enumerate}
\vspace{-2.8mm}\item
\vspace{-2.8mm}\item
\end{enumerate}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% enumerate 列举样式2:(1) (2) (3) (4)
\begin{enumerate}
\renewcommand\labelenumi{ \theenumi }%就在前面那个括号的空格处加符号
%\setlength\itemindent{}%这个会使列举的左移或右移指定的距离
\vspace{-2.8mm}\item
\vspace{-2.8mm}\item
\end{enumerate}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%图形插入样式
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%图形排版样式1:定点
%图形排版时名称一般都在下方
\begin{center}
\includegraphics[width=10cm,height=6cm]{*.eps}%就在前面括号中写图片名
\renewcommand{\figurename}{图}
\caption{}
\label{}
\end{center}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%图形排版样式2:浮动
%图形排版时名称一般都在下方
\begin{figure}
\begin{center}
\includegraphics[width=10cm,height=6cm]{*.eps}%就在前面括号中写图片名
\renewcommand{\figurename}{图}
\caption{}
\label{}
\end{center}
\end{figure}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%图形排版样式3:两个图片并列,统一取名
%图形排版时名称一般都在下方
\begin{figure}
\begin{center}
\begin{minipage}[c]{0.5\textwidth}
\centering\includegraphics[width=5cm,height=3cm]{*.eps}%就在前面括号中写图片名
\end{minipage}%
\begin{minipage}[c]{0.5\textwidth}
\centering\includegraphics[width=5cm,height=3cm]{*.eps}%就在前面括号中写图片名
\end{minipage}
\renewcommand{\figurename}{图}
\caption{}
\label{}
\end{center}
\end{figure}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%图形排版样式4:两个图片并列,分别取名
%图形排版时名称一般都在下方
\begin{figure}
\begin{center}
\begin{minipage}[c]{0.5\textwidth}
\centering\includegraphics[width=5cm,height=3cm]{}%就在前面括号中写图片名
\renewcommand{\figurename}{图}
\caption{ }
\label{}
\end{minipage}%
\begin{minipage}[c]{0.5\textwidth}
\centering\includegraphics[width=5cm,height=3cm]{}%就在前面括号中写图片名
\renewcommand{\figurename}{图}
\caption{ }
\label{}
\end{minipage}
\end{center}
\end{figure}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%图形排版样式5:两个图片作为子图并列,分别取名。四个可形成图形阵列。在下方有一个总名称
\begin{figure}
\centering
\subfigure[子标题]{\includegraphics[width=0.45\textwidth]{*.eps}}
%\mbox{\hspace{0.5cm}}
\subfigure[子标题]{\includegraphics[width=0.45\textwidth]{*.eps}}
\\
\subfigure[子标题]{\includegraphics[width=0.45\textwidth]{*.eps}}
%\mbox{\hspace{0.5cm}}
\subfigure[子标题]{\includegraphics[width=0.45\textwidth]{*.eps}}
\renewcommand{\figurename}{图}
\caption{总标题}
\label{}
\end{figure}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%图形排版样式6:图片在盒子中
\begin{figure}
\begin{center}
\fbox{\includegraphics[width=10cm,height=6cm]{*.eps}}%就在前面括号中写图片名
\renewcommand{\figurename}{图}
\caption{}
\label{}
\end{center}
\end{figure}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%图形排版样式7:图文混排,段落插入图片用picins宏包和\parpic命令
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%
\parpic{%
\includegraphics[width=3.0cm]%
{*.eps}}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 表格样式
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 基本表格样式
% 在下面那个括号中,用|表示画竖线,而l表示单元格中的内容在单元格中左对齐,
% c表示单元格中的内容在单元格中中对齐,r表示单元格中的内容在单元格中右对齐。
% 如|c|c|c|就表示画一个3列有竖线的表,当然|也可略,就不画竖线出来;
% 用\hline画横线,一般是表的一行内容输入完并强制换行(\\)后,在后面写
% \hline,然后后面再写下一行内容。当然\hline也可略,就不画横线出来;
% 下面这个表格是一个3行3列的表格
\begin{tabular}{|c|c|c|}
\hline
*** & *** & ***\\
\hline
*** & *** & ***\\
\hline
*** & *** & ***\\
\end{tabular}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 下面这种形式可以指定表格的宽度。在下面那个括号中写上0.5\textwidth
% 就可得到一个半张纸宽的一个表格;
% 写上\textwidth就可得到一个整张纸宽的一个表格。
\begin{tabular*}{***}{|c|c|c|}
\hline
*** & *** & ***\\
\hline
*** & *** & ***\\
\hline
*** & *** & ***\\
\end{tabular*}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 表格样式1:标题在图表上方,去掉了冒号
\begin{table}
\begin{center}
%\makeatletter\def\@captype{table}\makeatother
\renewcommand{\tablename}{表}
\caption{}
\label{}
\begin{tabular}{}
\end{tabular}
\end{center}
\end{table}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%表格样式2:用tabularx宏包
\begin{center}
\begin{tabularx}{350pt}{|c|X|c|X|}
\hline
\multicolumn{2}{|c|}{Multicolumn entry!}& THREE& FOUR\\
\hline
one&
\raggedright\arraybackslash\setlength\baselineskip{12pt}
The width of this column depends on the width of the table.& three&
\raggedright\arraybackslash\setlength\baselineskip{12pt}
Column four will act in the same way as column two, with the same width. \\
\hline
\end{tabularx}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%表格样式3:高级表格控制
\begin{table}
\begin{center}
\scriptsize
\renewcommand{\arraystretch}{1.3}
\caption{Quasi-normal frequencies for the scalar perturbation in
the stationary Schwarzschild background. \label{tab:1}}
\begin{tabularx}{380pt}{*{5}{>{\centering\arraybackslash}X|}>{\centering\arraybackslash}X}
\hline &&\multicolumn{2}{c|}
{\textbf{Exact solution}}&\multicolumn{2}{c}{\textbf{Numerical solution}} \\
\hline
$\sqrt{M}$&$m$&$\omega_R$&$\omega_I$&$\omega_R$&$\omega_I$ \\
\hline
0.2&1&1&-0.4&1.002&-0.400 \\
0.4&1&1&-0.8&0.965&-0.799 \\
0.4&2&2&-0.8&2.003&-0.800 \\
0.4&3&3&-0.8&3.004&-0.800 \\
0.4&4&4&-0.8&4.005&-0.800 \\
0.5&2&2&-1&1.999&-1.000 \\
0.5&3&3&-1&2.993&-1.000 \\
0.5&4&4&-1&4.007&-1.000 \\
1&4&4&-2&4.004&-2.001 \\
2&10&10&-4&10.014&-4.001 \\
3&10&10&-6&10.028&-6.011 \\
4&10&10&-8&9.973&-7.983 \\
\hline
\end{tabularx}
\end{center}
\end{table}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%公式样式
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%摘引环境1:段摘引
\begin{verbatim}
\end{verbatim}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%摘引环境2:行内摘引
\verb|*********|
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%程序清单样式
\lstset{language=matlab}
\begin{lstlisting}[frame=trBL]{}
clf;
k=-80:80;
a(k~=0)=sin(pi*k(k~=0)/2)./(k(k~=0)*pi);
a(k==0)=0.5;
stem(k,a);
t=-3:0.01:3
\end{lstlisting}
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 参考文献样式
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
\small
\renewcommand\refname{\hei 参考文献}
\begin{thebibliography}{99}
\setlength{\parskip}{0pt} %段落之间的竖直距离
\bibitem{tang}
\bibitem{liu}
\end{thebibliography}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 参考文献结束
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
并列的子图形
27.3 并列的子图形
在某些情况下,有时会希望将并列的图形组成一组,而其中的每一幅图 都保持其独立性。 paisubfigure 宏包的 \subfigure 命令将这一 组做为一幅图形,其中的每一幅图做为子图形。例如: \begin{figure} 生成图 27.9。这里使用 LATEX 的引用命令 \ref{fig:subfig:a} 会得到 27.9(a), \ref{fig:subfig:b} 得到 27.9(b), \ref{fig:subfig} 得到 27.9。 | |
像其它的并列图形一样,子图也可以在小页环境中使用。而且在一些情况下, 这样做还能更方便的得到理想的图形间距。例如: \begin{figure} 得到图 27.10,其中包括两个子图 27.10(a) 和 27.10(b)。 | |
|
| |
图 27.10 中的子图标题比图 27.9 中的要宽一些。 这是因为子图标题的宽度和子图的宽度相同,图 27.9 中的子图 只包含图形,而图 27.10 中的子图包含了宽度为 0.5\textwidth 的小页。 子图的标记有两种形式:
| |
如果改变子图标题的标记,字体等的缺省值,可参见文献 [10]。下面 给出几个简单的例子:
| |
缺省情况下,用 \listoffigures 命令生成的图形目录中只包括图形, 而不包括子图。要想在图形目录中包括子图,要在 \listoffigures 命令前加上 \setcounter{lofdepth}{2}。 需要说明的是,由于 LATEX 的变化,导致目前版本(3/95) 的 subfigure 宏包在图形目录的子图输入项开始部分都加上 ``numberline1''。将下面的代码加到导言区中就可以解决这一问题。 \makeatletter |
![\includegraphics[width=1in]{graphic.eps}](http://www.ctex.org/documents/latex/graphics/img134.gif)
![\includegraphics[width=1in]{graphic.eps}](http://www.ctex.org/documents/latex/graphics/img135.gif)
Latex 图片
插入eps图片
使用\includegraphics[选项]{文件} 命令可以插入eps图片。下面是一个最简单的例子:
\documentclass{article}
\usepackage{graphicx} %使用graphicx包
\begin{document}
\includegraphics{file.eps} %插入图片,按图片原尺寸插入
\end{document}
注意:
(1)eps文件和tex文件放在同一个文件夹,只用文件名就可以调用,不用写路径。
(2)编译时不能使用pdflatex,会出错。即使不出错,也看不到图。应使用latex编译生成dvi,然后dvi2ps,ps2pdf就可以看到图了。
使用[选项]可以指定图片大小:
\includegraphics[width=3in]{file.eps}
设定图片宽度为3 inches,图片高度会自动缩放。
\includegraphics[width=\testwidth]{file.eps}
设定图片宽度为文本宽度。
\includegraphics[width=0.8\textwidth]{file.eps}
设定图片宽度为文本宽度的0.8倍
\includegraphics[width=\testwidth-2.0in]{file.eps}
设定图片宽度比文本宽度少2 inches。
使用[选项]指定图片旋转角度:
\includegraphics[angle=270]{file.eps}
将图片旋转270度。
两个选项同时使用,中间用逗号隔开:
\includegraphics[width=\testwidth, angle=270]{file.eps}
1,插入jpg图片
在命令行环境下,使用命令:
ebb figure.jpg
生成bounding box文件figure.bb。
使用如下命令:
\includegraphics[width=0.8\textwidth]{figure.jpg}
可以使用Pdf Texify直接编译成pdf文件。
2,插入bmp图片
还没有找到直接插入bmp图片的方法。现在的方法是,使用
gimp将bmp转换成jpg,然后按上述方法插入。转换时不要
使用windows自带的painter,图片质量损失太多。用gimp或
fastone image viewer,将jpg质量选为最高,转换之后得到的
图片质量较好。
3,同时插入jpg和eps图片
插入的命令不变。编译时使用Latex, dvi2pdf,两种格式的
图片都可以显示。
1,插入并列的子图
\usepackage{subfigure}
\begin{figure}[H]
\centering
\subfigure[SubfigureCaption]{
\label{Fig.sub.1}
\includegraphics[width=0.4\textwidth]{figurename.eps}}
\subfigure[SubfigureCaption]{
\label{Fig.sub.2}
\includegraphics[width=0.4\textwidth]{figurename.eps}}
\caption{MainfigureCaption}
\label{Fig.lable}
\end{figure}
2,控制图片位置
如果不喜欢让Latex自动安排图片位置,可以使用float包,然后
用\begin{figure}[H]。
\usepackage{float}
8.25.2008
计算机科学的论文
一.计算机科学的中文论文
因为在校内的原因,一直以来只选择维普科技期刊中文数据库
二.计算机科学的英文论文(按使用偏好)
1. Google Scholar
Google Scholar对每一篇paper一般能返回若干个结果,可以点开group看,默认结果通常是链接向ACM或者IEEE的Digital Library的,是收费的。如果你的学校没有订阅的话,你是下载不了的。所以最好在group里面寻找一个链向作者主页的,实验室主页之类的,通常可以 直接下载。Citeseer 里面,很多文章的电子版都直接在citeseer的数据库里,可以直接下载。DBLP本身不提供论文下载,但是相当一部分paper是有链接指向ACM和 IEEE的。DBLP的好处是对论文进行了系统的分类,按作者,按会议,按期刊等等。Citeseer主要是根据citation来把paper串起来 的。
2.Citeseer
3. DBLP
4. IEEE Computer Society Digital Library
如果你跑到ieee.org
5.寻找BibTeX
如果你用LaTeX写论文的话,手边备有几个地方可以找到现成的BibTeX entry还是很省事的(平时自己一定要积累,比如没看一篇paper,都把相应的bibtex entry整理好,放进自己的bib文件)。
在ACM Digital Library
6. 论文作者主页或其它收藏有此文的个人主页
7. ACM portal 全文下载收费, 学校就没有购买:(
8. 求助于国内各学术论坛。
首先使用1,因为1是最全面的搜索平台,能够显示出目标论文出现的位置或直接下载的链接,可能出现在IEEE xplore、ACM portal、CiteSeer等数据库内或个人主页上,大多时候会出现作者DBLP信息。
然后,进入相应的数据库或页面进行查阅下载。
如果没有购买相应的数据库,可以试试CiteSeer或网上的个人主页,很多论文可以从这里可以免费下载。
如果想要打开某个作者主页或找出其发表的所有论文,推荐使用DBLP。
最后必杀技 (8): 就是各大学术论坛发贴求助,有时候这是最直接有效的,参考学术论坛推荐
--------------------------------------------------------------------------------
给出部分搜索英文论文的网站
http://ieeexplore.ieee.org/
http://citeseer.ist.psu.edu/
http://dblp.uni-trier.de/
http://www.computer.org/portal/site/ieeecs/index.jsp
http://smealsearch2.psu.edu/index.html/
http://portal.acm.org/portal.cfm
http://www.vldb.org/
http://scholar.google.com/
--------------------------------------------------------------------------------
在google或yahoo上搜索CiteSeer数据库的技巧:
在搜索栏内输 keyword site:citeseer.ist.psu.edu/
上面的keyword 还可以用引号引入多个,如:
"keyword1 keyword2" site:citeseer.ist.psu.edu/
--------------------------------------------------------------------------------
What is DBLP
DBLP, a computer science bibliography site, was originally a database and logic programming bibliography site, homed at Universit?t Trier, in Germany, and has existed at least since the 1980s. As of November 2004, DBLP listed 566,666 articles on the computer science field, mirrored at five sites across the Internet. Some of the journals which are tracked on this site include VLDB, a journal for Very Large Databases, and the ACM Transactions. (from en.wikipedia.org/wiki/DBLP)
8.22.2008
latex显示源代码
latex显示源代码
使用\verb或者verbatim环境 显示latex的源代码, 也可以用listings宏包.
一个例子
\documentclass[11pt]{article}
\usepackage{verbatim}
\usepackage{comment}
\begin{document}
This document demonstrates the \verb=verbatim= environment
and \verb=\verbatiminput= command. It also demonstrates the
\verb=comment= environment, but you have to look at the TeX
source to see that (of course).
Here is a short piece of Maple code to demonstrate the
the \verb=verbatim= environment:
\begin{verbatim}
> eqn:=diff(y(t),t,t)+4*y(t)=0:
> inits:=y(0)=1,D(y)(0)=-1:
> dsolve({eqn,inits},y(t));
\end{verbatim}
$$
\mathrm{y}(t)= - \frac{1}{2}\,\sin(2\,t) + \cos(2\,t)
$$
\begin{comment}
Put a few paragraphs you have not decided about yet here for future
work. They will not appear in the output. You can also put comments
or reminders here. For example, you may want to remind yourself that
Maple has a nice LaTeX export feature which may be more convenient
than the by-hand approach used above.
\end{comment}
To demonstrate the \verb=\verbatiminput= command this file will
input itself, which is pretty cool. To make sure
this file can find itself to input, we use the \verb=\jobname=
command in the argument to \verb=\verbatiminput=. Thus everything
will work even if you rename this file.
\end{document}
-------------------------------------------------------
使verbatim环境在XeTeX下支持中文
研究了一下verbatim.sty,发现verbatim环境默认使用ttfamily的字体,因此只要重定义
\verbatim@font宏使verbatim默认使用rmfamily或sffamily字体,通过\setromanfont或
\setsansfont设置相应字体族为中文字体即可。
\documentclass[a4paper]{article}
\usepackage{fontspec,xunicode,xltxtra,verbatim}
\setsansfont[BoldFont={"[simhei.ttf]"}]{"[simsun.ttc]"}
\setromanfon[BoldFont={"[simhei.ttf]"}]{"[simsun.ttc]"}
%设置字体时也可以直接用字体名,以下三种方式等同:
%\setromanfont[BoldFont={黑体}]{宋体}
%\setromanfont[BoldFont={SimHei}]{SimSun}
%\setromanfont[BoldFont={"[simhei.ttf]"}]{"[simsun.ttc]"}
%但是不推荐使用第一种方式,对于中文名称的字体,使用该方式会导致不能将
%roman、sans族字体设置为同一种字体,比如将romanfont和sanfont都设置为"宋体"
%将导致编译错误。但是用另外两种方式却没问题,也许是fontspec包的bug吧。推
%荐直接指定字体文件名的第三种方式。
\begin{document}
Can you see some CJK characters in the verbatim?
\makeatletter
\def\verbatim@font{\sffamily\small} %如果使用roman字体族,将sffamily改成rmfamily
\makeatother
\begin{verbatim}
some ascii characters!
你能看到中文字符嘛!
\end{verbatim}
\end{document}
ps: 此文最初发表于水木清华TeX版
from: http://www.365bloglink.com/go.php?id=soGuWt3ui
--------------------------------------
用LaTeX写论文时,插入C++源代码有专门的宏包,方法如下:
\usepackage{listings}
\lstset{language=C++}%这条命令可以让LaTeX排版时将C++键字突出显示
\lstset{breaklines}%这条命令可以让LaTeX自动将长的代码行换行排版
\lstset{extendedchars=false}%这一条命令可以解决代码跨页时,章节标题,页眉等汉字不显示的问题
\begin{lstlisting}
%paste your C++ code here
\end{lstlisting}
from: http://yichangren.blog.hexun.com/9057534_d.html
论文编译程式Latex 介绍
(本文为自由发布的文档,你可以对其进行任何的拷贝,传播,修改。但原始文档版权仍归原作者所有。如有直接引用的情况,请注明文档出处和作者姓名)
(本篇介绍在写作过程中参照了多篇网络上的教程及帮助文档,在此对那些作者表示感谢,感谢他们为我们做了绝大部分前期的文档工作,由于太多,此处不一一列 举;另外也感谢王垠,是他带给我去坚定地使用Linux和Latex的意志――这意志帮助我克服了学习过程中的种种困难;最后感谢图灵奖得主Knuth教 授,感谢他做出伟大的TeX出来,供后人使用。)
第一章:我为什么用Linux
Latex是什么,说它是一个“排版软件”,可能大家都会莫名其妙,我要一排版软件来干什么?但是如果我说它是一个“写论文用的软件”,那你可能就会很有兴趣了。毕竟作为大学生,不可能不写论文的。
其实Latex不仅可以写论文,还可以处理日常生活中的各种文档工作。如写信,写书,画表格,甚至做幻灯片(对,我没打错,它就是可以做幻灯片,而且很容易就能做出世界一流水平的幻灯片)等等。
本文纯粹是从使用者的角度来讲解Latex的使用方法的(当然,这样说的原因在于我本身尚未深入地研究TeX的底层体系),因此力求讲得通俗易懂。如果有什么不妥或不完善的地方请大家能时指出,欢迎热烈批评!
我们为什么要用Latex?
你一定会说日常生活中的各种文档工作不是用WORD就能进行处理了吗,何必那么麻烦再去学习一样新的东西呢?不是的。世界上还有很多更优秀的东西我们还没 有发现,如果能掌握这些更优秀的工具,那么工作效率会事半功倍。可以说当今中国的大学生们(包括中国的很多大学教授们)的计算机方面的思想已经被微软所固 化了。“言文字处理必谈WORD”,“言程序开发必学VB, VC”,“言操作系统必选WINDOWS”。我这儿并不是想排斥微软,打倒微软什么的,(诚心地说它毕竟还为推动中国的信息化的进步做出了很大贡献)我只 是想说明作为优秀大学的学生的我们,作为中国21世纪的主力军的我们,不能再被一种并不先进的思想所禁锢了!我们必须掌握最先进的最有前途的思想,知识和 能力。而TEX就是这种先进思想的典型代表。
它是计算机科学家图灵奖得主Knuth教授设计的一款权威的科技论文排版软件!更重要的它是开源 (Open Source)的,Knuth教授无偿公开了它的所有源代码。正因为这个原因,无数的爱好者们大胆尝试TeX。并在其基础上开发了一个宏集 ――Latex。Latex方便好用,被广泛传播,成了当今世界科技界最权威的论文排版软件。
下面,我就来详细地比较一下Latex与WORD各自的优缺点。
1:“所想即所得” vs. “所见即所得”
WORD所遵循的思想是“所见即所得”。因此,用它写东西非常直观。而且打印的效果与在屏幕上看到的效果一模一样。另外,它还具有一定的智能化(尽管这个功能很多时候会帮倒忙)。
而Latex所遵循的思想是“所想即所得”。意思就是你脑子里想到什么,就可以做出什么样的版式效果来。这说明它有非常强大的功能,但对这一种强大的掌握有一条相对来说陡峭一点的学习曲线。
用WORD写文章直接往里面写就行了,然后用那些数不清的格式按钮对文档进行格式编排。写这些文档必须在WORD软件环境里面(你无法拿记事本来写.doc的文档)。
而用Latex写文章可以使用任何一个文本编辑器。Latex有它自己专用的文件后缀名,但它的格式完全是文本文件格式。这意味着你可以使用vim,gedit,记事本等中的任何一款写Latex文档。只不过在保存文件时把后缀名改.txt为.tex就可以了。
用Latex写文章需要像写程序那样来写(请不要为我的语言所吓倒,那不是像C语言那样的程序代码,要简单得多),写完之后再编译。初看起来这不是自找麻 烦吗?仅仅写一篇文章就要编个程,是不是有病了。不是的,你仔细想想:一篇论文不仅包括文字,还有图片,表格,公式(对我们来说很重要),还有很多各种各 样的细微的格式和版式。把这些因素加在一起,就不是仅用WORD就能很好地处理的了。而对Latex来说,这些都是小菜一碟。
Latex文档中,是通过插入一些标记符来标记其逻辑结构的(这方面它和HTML, XML有点类似)。这些标记符都是一些常用的英文单词,十分好记。只要花点时间用熟悉了,就可以很快地写出一篇格式漂亮的文章出来。
万事开头难嘛,最难的不是记忆那些命令,而是转变一种思维,就像使用LINUX一样。(Latex和LINUX搭配是天籁之合,我的讲解也是以LINUX上的Latex为主。建议大家读读王垠的《完全用LINUX工作,摈弃WINDOWS》)
2:如果你经常编排带数学公式的文章,你可能会发现,WORD编排出来的段落不是那么令人满意,如果左对齐,那么每行的右边参差不齐,很不美观;而如果 选用两边对齐,那么WORD为了达到这点要求,可能就加大了某些词与词之间的间距,那样也达不到我们满意的文章格式。能不能在行末自动地把一个单词在音节 处拆开, 并加上连字符呢? Latex可以。
你一定对MathType不陌生。公式编辑器用多了,你可能就发现,WORD把公式当作图片来处理。如果你要修改文章字体的大小,这时需要一个一个地调整 公式的大小,这简直是无法承受的工作量;而且,你经常会发现,WORD的公式大小并不是和正文那么适配,许多时候看起来要么大了,要么小了,尤其是碰到大 行的公式,页面编排都可能因此受到影响了。而LatexX美观的公式混排,统一的公式正文大小,会令你有耳目一新,相见恨晚的感觉。
3:你是否有这样一种经验:当你用WORD写完一篇大一点的含有很多插图,表格和公式的论文交给导师审阅后,导师要求你在某个地方再详细一点,多列一些 数据,多插几幅图片;而在另外一些地方简略一点。这时你不得不插入新的图片(表格,公式),结果一插,把后面的原先排好的版式全打乱了。这样你又不得不重 新排一遍,排好后,检查时,又发现哪个地方公式不对,得重新写。于是用MathType写了一个“体积”大一点的公式,再插入文档中,结果又发现,后面的 版式又莫名其妙地被改动了。又得重新来一遍,气死人了。就这样反反复复,一个本来不复杂的工作耗费了你太多的时间,同时把心情也搞孬(我们念pie,四 声)了。真不爽!
还有在论文中每个图(表,公式)都有编号,当你插入一个新的图时,就打乱了先前的编号顺序,所以你还得一个一个地将先前的位于这幅图片后的那些图片(表 格,公式)的编号手工改正过来。天哪,这又是一件多么恐怖的事情――我这可是科技论文啊?密密麻麻的图片,公式。你叫我如何改啊!而且这还是一遍,说不定 要使一篇论文最终定稿要改N次呢!
现在你是否感觉到已经忍受不了呢?你需要一种解脱。不用怕,不用恼,救星到来啦!Latex,专门解决这个问题。
Latex处理这个问题是基于如下一种机制:
它完全用一种逻辑结构标记符来标记哪里是文章题目、作者,哪部分是摘要,哪里是小节标题,哪里是图片,哪里是表格,哪里是公式,哪里是脚注,哪里是页眉, 哪里需要两栏排版,哪里则只用单栏等等等等。它对每种不同的对像都设计了一个计数器,用来记录这一类型的对象到现在是第几个。比如图片计数器,编译程序在 编译时会按从前到后的顺序寻找论文中所有图片,并且找到一个便给它编一个号(从1号开始依次递增),一直到文章末尾。
利用这种机制,即使在中途又插入了很多新的图片(表格,公式)的情况下,只要它们的逻辑顺序是对的(废话,逻辑顺序不对就是你写论文的水平不够了!), 那么Latex就会重新从头到尾再编一次号,这样前述的那种令人头痛的问题就迎刃而解了。思想就是把无谓的重复劳动拿给机器处理,机器处理这些小东西来速 度是不用担心的。于是,你被解放出来了!什么是工作效率,这就是!
4:很重要的一个问题是:WORD不太稳定。当你编辑一份含大量公式的文档时,会发现WORD有时会crash,有时甚至会莫名其妙地消失。这时如果我们的工作还未保存下来的话,那就太不幸了,只有重新输入一遍。而且弄得自己人心惶惶的。
Latex就不存在这个问题,它是一种纯文本格式,所占用的空间(硬盘,内存)极小。再加上极稳定的编辑器VIM,几乎不会出现crash的现象。
5:从美学观点来看,我实在不敢敬同WORD中的公式佷漂亮这一说法。你去图书馆随便找一本比较有名气一点的外文杂志或外文著作。它们那里面的公式多么 漂亮,整体布局多么赏心悦目。虽然我不敢说那些书全是用Latex编排的,但至少可以说明一点:WORD中的公式符号不好看。虽然我不敢说那些书全是用 Latex编排的,但我敢说那些书里面大部分都是用Latex及类似的(基于TeX的)软件包编排的。不信,你去比较一下那些书里面的符号和Latex教 材(外面书店有卖的)里面的符号形状是不是一样的。有点使用Latex经验的人一眼就可辨别其中奥秘。
这是什么意思?
对!它意味着,使用Latex,你能用很简单的方法排版出具有专业水准格式的论文和杂质甚至书籍出来!
6:比较现实的是,现在很多国内外杂志,要求寄去的文章按Latex格式排版(可能有些杂志可以接收WORD文档,那你可能又要在茫茫软件海洋中寻找英 文WORD,因为国外根本就没有中文WORD,而你的中文WORD文档在英文WORD中什么都看不出来)。那么会用Latex就更是你迫在眉睫的需要。
Latex就和vi一样,在你对他一点不懂的时候,你总觉得他很难相处,但是在你了解他之后,你会越来越发现他的好。然后会爱不释手,然后会五体投地,然后会――进步:-)
Latex讲解第二章:Latex发行版的版本和使用基本方法
Latex软件的版本
Linux和Windows平台都有各自的Latex版本。Linux下的版本主要是teTex,Windows下的版本主要有mikTex。而中国有 一个比较著名的版本CTeX,它是CTeX中文套装的简称,属于二次开发版本。它是把 mikTex和一些常用的相关工具,如GSview,winEdt,yap等包含在一起制作的一个简易安装程序。并且它对其中的中文支持进行了配置,使得 安装后马上就能处理中文。
GSview是一个浏览.ps(一种打印格式)的工具。
winEdt是一个专为TeX用户设计的编辑器。(但是用过它的人都会感觉到,这个编辑器打开速度太慢,功能难用,字体,界面也不好看。难怪经常被网上的人骂为垃圾)
yap是用查看.dvi格式的一个工具,支持“反向位置查找”功能。(这个用起来还不错)
而Linux下的teTeX,我并没有直接使用。我用的是由CTAN组织制作的一款软件包TeXLive2004(以TE为核心),里面包含了几乎所有的宏包,文档及查看、转换工具。我们常用到的主要有如下几个:
latex 用于编译.TeX文档(这个是核心)
xdvi 用于查看.dvi文档(这个文档是由前面那个.TeX文档经编译后生成的)
dvipdfm 用于将.dvi文件转换成.pdf文件。
转换成.pdf文件后,就可以方便地与别人交流了。(要知道,pdf格式可是当今世界上的几乎所有较正式的组织的电子档案的首选保存格式呀。比如,AD公司(www.analog.com)的所有芯片的技术资料全是以pdf格式提供)
而据我的使用经验,TeXLive2004安装程序并不太适合中国用户,因为它完全不含有任何一种中文字体(当然,每一款比较好的中文字体都是有版权的),尽管网上有怎样添加的方法,但是要添加起字体来特别特别麻烦――我前段时间一直为此大伤脑筋呢!
于是我将其中的绝大部分东西抽取出来,与我搜集的十三种中文字体(转换后的。注:那些字体那是有版权的,请不要用于商业目的)合起来做成了一个软件包。同 时还对里面的一些配置文件作了修改,使Linux下的用户直接也能使用中文字体了。(我称其为Latex2004完全版,包里面有详细的安装说明文档)
到现在,可能大家会有这样一个疑问:现在软件有了,那该怎样使用呢?而且前面介绍那么多工具。那么用LATEX写论文到底是一种什么流程呢?下面就来回答这个问题。
下面就以一个实例来说明。
第1步:编写好一个.tex文档。并保存。假设文件名取为example.tex,存放在~/work/目录下。
第2步:打开一个终端。输入 cd work 进入到~/work/目录下。
第3步:在终端中输入 latex example.tex 对example.tex这个文档进行编译。通过编译,会生成一个新文件:example.dvi(当然原来那个example.tex文件还在那里,没有消失)。
.dvi文件是“与设备无关的文件”,这里的设备指CPU、显示器,打印机等。这意味着这种格式的文件无论在哪台机器上,无论是怎样的显示器,无论在哪个操作系统上,看到的效果都完全是一样的。
当然,这样一种格式的文件得用专门的工具来查看。Linux下,这个工具就是xdvi。
第4步:在终端中输入 xdvi example.dvi 就可以查看刚才由.tex文档生成的.dvi 文件了。在这一步中,你可以检查你所输入的那些东西是不是都出应有的效果了(当然,这个应有的效果就是你头脑中的预计――所想即所得,就初步体现在这里 了),如果发现有错误的文字或不合适的版面,那么就可以再回到第1步去,修改后,再编译,再查看。直到自己满意为止。
第5步:在终端中输入 dvipdfm example.dvi 就会将example.dvi文件转换成为 example.pdf 文件。这时就可以用pdf浏览器查看了。
至此,一篇论文就基本完成了。归纳起来,就是如下步骤:
latex dvipdfm
.tex------->.dvi------->.pdf
下一章,我就将开始正式讲解怎样写latex文档。
Latex讲解第三章:Latex文档的基本结构及基本样式
首先建议大家如果真的有心学,最好是去书店里买本书仔细看看,因为细节知识是非常多的。我这里只能讲解一些概要,不可能面面俱到。
Latex文档的基本结构如下:
文档类型声明
宏包包含区
自定义命令区(全局设定区)
标题区
正文区--------正文
|
-----参考文献
将上述结构翻译成代码即为如下:
%文档类型声明
\documentclass[a4paper,11pt,onecolumn]{article}
%宏包包含区
\usepackage{CJK}
%自定义命令区(全局设定区)
\renewcommand{\baselinestretch}{1.5} %定义行间距
%标题区
\title{ }
\author{ }
%正文区
\begin{document}
....
\end{document}
上述即为Latex文档的基本结构了。大家可能还不十分懂这些命令到底起什么作用,但是根据各个英文单词的含意,应该能够猜测到一些意思了吧。同时,这也展示了Latex一个特点:每个命令都使用完整的很容易懂的英文单词,而不是缩写,所以很明了,学习起来不难。
下面我给出一个英文文档的基本例子。
\documentclass[a4paper,11pt]{article}
\begin{document}
Hello, world!
\end{document}
就这样四行简短的代码,会得到图1的效果。
\documentclass[a4paper,11pt]{article} 用来说明你这篇文章用多大的纸,默认多大的字号,并且文档类型是什么。\documentclass 是命令,是每一篇文章开头必须写的。a4paper 指定现在用A4的纸;11pt 指定默认字体的大小;article 用来说明这篇文档是篇论文(当然计算机是不会认得你要写论文的,只不过它预先定义了一些格式,以article 称呼的这种格式适用于论文,所以就叫它为论文格式了)。
字体大小那个选项一般不行去改动它,不写也行,系统默认为11pt。不写的话就为:\documentclass[a4paper]{article}。写论文一般用A4的纸,当然,与这个选项对应的其它选项还有b5paper 等,可根据实际需要来改变。
而article 这个位置一定不能空。与之对应的参数有 book(书), report(报告), letter(信件) 等。
然后是\begin{document}和\end{document},这也是两个必须写的命令,它们是一对语句,不能只写一个而不写另一个,即必须匹 配。而且在一篇文档中只能写一次这对语句。从这对语句中又可反映出Latex的一个特点:很多语句是成对出现的,而且命令名都是\begin{}和\ end{}的形式。
\begin{document}和\end{document}中间的那个 Hello, world! 就是文章的内容了。你在图1中看一下,是不是在左上角有个 Hello, world! :-)
好了,就这样一个文档就写好了。简单吧。
但──一个严重的问题是:这个文档只能处理英文。只要打一个汉字上去,在编译时就会出错!怎么办?
下面我就来详细讲一讲 Latex 是如何处理中文的。
Knuth 在发明 TeX 的时候,根本没有考虑到还要处理中文字符(以及其它许多亚洲字符)──它发明 TeX 的目的就是为了排版它的巨著《计算机算法艺术》。尽管这样,Knuth 却采用了一种先进的设计思想,从底层留下了扩展接口,并将其全面公开。这样,当时他本人没有实现的一些功能,就可以通过宏包的形式加以扩展实现。这就是为 什么到现在为止 30多年过去了,TeX 在底层还几乎没有改动(只发现两处小错误)。说到这里,确实不得不佩服Knuth,什么叫牛人,这就是。计算机科学家写出的软件与一般程序员的软件就是不 同!
Latex中处理中文,需要用一个叫做 CJK 的宏包(宏包就是预先定义了一些命令及格式的一个文档,学过 C 语言的同学都应该了解的)。
CJK是由Werner Lemberg开发的支持中、日、韩、英文字的宏包。CJK的特点是不需要象CCT那样预处理,支持PDFLatex和Type1字体,因此得到越来越多 中国TeXer的喜爱,逐渐成为中文LaTeX的主流。而我提供的那个包里面就已经含有了。(可以毫不夸张地说,几乎所有已经出现的宏包在那个软件包里面 都有自己的位置)
这个宏包通过一个字符映射表,来实现汉字的处理。讲下去就比较深了,这里暂且说到这么多。
下面我就给出一个处理中文的基本样例。
\documentclass[a4paper]{article}
\usepackage{CJK}
\begin{document}
\begin{CJK*}{GBK}{song}
你好,世界!
\end{CJK*}
\end{document}
生成的效果图如图2 。
下面细细讲解一下新增的语句的作用。
\usepackage{CJK}表示把CJK这个宏包包含进来。\usepackage{ }就是包含宏包的命令。
\ begin{CJK*}{GBK}{song}和\end{CJK*}是中文字符的定界语句。意思就是要想显示中文,就得用这两句把所有中文包含起来。当 然,英文字符在这里面是不受影响的。\begin{CJK*}{GBK}{song}中的最后一项,就是指宋体的意思。(我的安装包说明里面有十三种字体 对应的符号名字。在Latex中使用时就用那些符号名字。)当然,你可以把它改为 kai(楷书), hei(黑体), xihei(细黑), li(隶书) 等等。
比如我将song改为kai,那么将得到如图3的效果。
看,用Latex写中文文档也不复杂吧。这个文档还太小,还体现不出Latex的优势,以后用熟了,写大文档了,就能深刻地体会到了。
在这里,我要着重强调一下,Linux下的字符编码问题。
现在的Linux基本上都通用UTF-8编码作为其默认编码,这是事实,我们最好不要去改变它,否则很多程序的字体会出理乱码。但Latex无法支持 UTF-8编码(其实可以支持,但是好像要下一个宏包,在我提供的那个里面没有,我也没用过,不会用)。于是我们后退一步,绕过这个问题。在把文档写好 后,只要保存时选定编码就行了。
具体这样来实现:
对gvim来说,把文档写好后。在命令模式下,输入
set fileencoding=GB18030
如果程序提示modifiable if off。那么,可以先输入
set modifiable
再输入
set fileencoding=GB18030
就可以保存为GB16030编码的文件了。这样在编译时,才不会出错。
对gedit来说,把文档写好后,只需要点击保存按钮。就会出现一个保存对话框。如图4 。在此对话框的下面的字符编码中选择GB18030就可以了(没在列表中的话,可以添加)。
由于保存时忘记理性编码而出现编译通不过的情况经常发生,而且还会感觉莫名奇妙。所以大家在发现编译通不过时,首先就查一下是不是编码问题。
Latex讲解第四章:Latex内容总体概观(最后一章)
我写这四篇讲解的目的是因为我怀着这样一种心理:我学习Latex的过程中遇到了太多的困难,花了太多的时间,费了太多的精力(买了一本教材但是是很老 的,与当前版本不适合)。我不希望每一个想学习Latex的人因为计算机和教程的原因(网络上也有很多教程,但是大多是英文的,中文的教程都不是很完整, 适用于初学者的不多,而且过滤这些信息要花大量时间)而半途而废或代价太高。因此我觉得自己有义务要把自己的亲身使用经验告诉大家。
由于本讲解只是入门性的介绍,目的是给大家介绍这么一款软件和思想,同时让大家了解基本的操作。故不打算再做更深入的讲解了。正所谓“师傅领进门,修行 靠个人”,要想真正的掌握它,就得由大家自己去找书看,去上网问了。同时,学习这个软件,必须要学会思考。不思考的人永远学不会。
这一章,我就来列举Latex里面主要包括哪些知识。
字符集
文字字符集
数字字符集
环境集
居中
\begin{center}
\end{center}
左对齐
\begin{flushleft}
\end{flushleft}
右对齐
\begin{flushright}
\end{flushright}
列举环境
\begin{itemize}
\end{itemize}
\begin{enumerate}
\end{enumerate}
保持环境
\verb| |
\begin{verbatim}
\end{verbatim}
小页环境
\begin{minipage}{size}
\end{minipage}
诗歌环境
\begin{verse}
\end{verse}
浮动表格环境
\begin{table}
\end{table}
固定表格环境
\begin{tabular}
\end{tabular}
浮动图片环境
\begin{figure}
\end{figure}
数学环境
$ $
$$ $$
\begin{equation}
\end{equation}
\begin{array}
\begin{array}
\begin{eqnarray}
\end{equarray}
10种字号命令
{\tiny }
{\scriptsize }
{\footnotesize }
{\small }
{\normalsize }
{\large }
{\Large }
{\LARGE }
{\huge }
{\Huge }
英文字体命令
{\rm } 罗马字体
{\bf } 黑体
{\it } 意大利字体
{\sc } 小号大写字体
{\sl } 斜体
{\tt } 打字机字体
{\cal } 花体
{\em } 强调型字体
几种数字的格式
\arabic{}
\roman{}
\Roman{}
\alph{}
\Alph{}
命令
文献头命令
标题命令
\title{ }
作者命令
\author{ }
日期命令
\date{ }
页注命令
\thanks{}
\footnote{}
章节命令
部分命令
\part{}
章命令
\chapter{}
节命令
\section{}
\subsection{}
\subsubsection{}
\subsubsubsection{}
附录命令
\appendix{}
使用上面所说的命令,处理一般的文字文档应该没多大问题了。但是一篇文章中还有三个很重要的部分:公式,图片,表格现在我们还没法处理。
下面就来讲一讲。
数学格式命令
很多,这里就不写出来了。我提供的资料中有很多是讲这个的。我这里就举一个例子,让大家见识一下Latex中处理公式的思想。
薛定谔方程
$$i \hbar \frac{\partial}{\partial t}\psi(r,t)
= [-\frac{\hbar^2}{2m}\nabla^2+V(r)]\psi(r,t)$$
此方程效果如图1,怎么样,感觉不错吧。
上面式子中用$$ $$括起来的部分,就是公式的Latex写法。大家肯定吓一跳吧。其实思路很简单,它就是定义了一套规则(如^表示上标,_表示下标,\frac{}{} 表示分数,第一个括号中的是分子,第二个括号中的是分母)和一些特殊字符表示方法,通过这个规则Latex能够实现将一个二维的公式写法化为一维的表达式 写法。这样就便于用文本文件的方式进行存储,并用Latex编译程序进行编译再现。而且这种写法有个好处是很容易扩展。这种思想就需要自己慢慢去体会了。
插入图片
这个需要详细说明一下。
Latex中只支持*.eps格式的图片。因此在插入时,如果不是.eps格式的文件,则首先要用GIMP或ImageMagick工具包转换 到.eps格式。然后把图片放到与.tex文件同一个目录下。(务必注意,我在初学时就是因为不知道把图片放在哪里而浪费了一个通宵)
Latex文档中本身并不包含图片,它是在编译时加载图片。而且在加载时,还可以控制图片显示的长度和宽度。
要在Latex文档中加载图片,必须要包括graphicx宏包。
下面即是典型代码:
\begin{figure}
\begin{center}
\includegraphics[width=10cm,height=6cm]{1.eps}%就在前面括号中写图片名
\renewcommand{\figurename}{图}
\caption{}
\label{}
\end{center}
\end{figure}
这段代码功能是把名为1.eps的图片调进来,放在浮动图片环境中,并居中放置。
\includegraphics[width=10cm,height=6cm]{1.eps}中的\includegraphics 即为调用图片的命令。[]中的参数用于指定加载图片后图片显示的宽度和高度。
\renewcommand{\figurename}{图}用于将其默认的标号(为figure)改为“图”
\caption{}给这幅图片取一个名字或作一段说明用于显示出来。
\label{}中也写一个名字用来标明这幅图片,方便前面或后面的交叉引用。
插入表格
插入表格没有图片步骤多,但也要注意一些细节问题。
\begin{table}
\centering
\renewcommand{\tablename}{表}
\caption{}
\begin{tabular}{|l|l|l|}
\hline
1 & 2 & 3\\
\hline
8.2 & 7.8 & 12.7\\
75.7 & 152.8 & 249.9\\
\hline
\end{tabular}
\end{table}
这段代码用来生成一个3行3列的浮动表格,并左右置中放置。
\begin{tabular}{|l|l|l|}中的|l|l|l|表示有三列,列与列之间用竖线隔开(共四根竖线)。
\hline表示画一根横线。
1 & 2 & 3\\中,&表示一个单元格与一个单元格的逻辑分隔符。而\\则表示换行。
好了,公式,图片,表格大家都见识过了。都有一个初步的印象了。下面就该自己去使用了,多练一练才会熟悉。
好,Latex内容的讲解就到此为止。
学习Latex,除了买本书来看外,还要注意以下几点:
1:仔细看书,打好基础;
2:要多练习,要多做笔记,善于总结;
3:多思考,因为是“先想才有所得”,才会实现“所想即所得”;
4:有不懂的问题要向周围会的同学多问,如果无人可请教。可以到论坛上去问,那里有非常多的热心人。并且要经常从论坛上收集或摘抄下很好的代码供自己使用。(积累啊)
5:有时不懂的问题用Baidu或Google也可以搜索出来哟。
6:不要怕看英文文档,那里面有最原汁原味的知识;
7:非常重要的一点,要学会做模板,并且要以做一个完全适合自己的模板为一大任务。尽管网上有很多很好的模板,但是不一定适合你。做好模板以后,你才会 发觉, Latex真的是太好用了,这次论文用的这个模板,无需修改或只修改一小部分就可以供下次写论文时使用。这样既提高了速度,又提高了正确率,而且有一个明 显的累积进步过程──这会使你感觉到很爽很充实的。
好了,废话就这么多了。
下面将搜集的资料分类整理如下,我将把它们上传到学生之家或5Come5服务器上。
整理中……
近日去学无涯书店(寓苑公寓下面)逛了逛,发现几本有关Latex的书,现介绍如下:
《排版软件LATEX简明手册》
罗振东 葛向阳 编著 电子工业出版社 2004
《TEX、AMS-TEX、LATEX使用简介》
李勇编 高等教育出版社 2000
《Latex2e 及常用宏包使用指南》
李平 清华大学出版社 2004
《Latex 入门与提高》
陈志杰、赵书钦、万福永编 高等教育出版社 2002
《Latex 实用教程》(英文影印版)
机械工业出版社 2005
下面是一些网站,丰富的信息在那里找吧。
CTEX 网站的网址为 http://www.ctex.org
CTEX 论坛的网址为 http://bbs.ctex.org
Latex(引用)
最近学会了使用Latex,并且今年的First Year Report就是用Latex写的,发现了很多也许有用的小技巧,总结一下。 我现在使用的是CTex,一个号称支持中文的Latex,不过我现在还用不上中文。该软件免费可下载:http://www.ctex.org/HomePage 里面的WinEdit确实是很好用的。编译的内核是MikTex 2.4,有一点老,不过基本功能都有了。 在linux上,可以使用texmaker,用了用,还是不错的。 插入图片。在Latex中,图片是以文件的方式嵌入到文档当中,在转换为pdf或者ps文件的时候才会嵌入到文件中,否则都是单独存在的。插入图片的基本命令: \begin{figure} \begin{figure}和\end{figure}中间是图片的命令。\centering之后的所有内容居中。 \includegraphics插入图片,width=0.6\textwidth说明图片的宽度为0.6倍页宽,文件名是 file/vcrouter,用latex编译自动搜索后缀为eps的图像,pdflatex编译自动搜索后缀为pdf的文件。\caption说明该图 片的标题,\label给出一个标签,文中则可以使用\ref{}进行连接。插入图片需要加载\usepackage{graphicx}。 插入多幅图片并包含子图的图片: \begin{figure}[ht] 这是一个两个子图水平并列的例子。在\begin{figure}后添加[ht]说明以水平table的形式排布,当然也可以使用tabular,不过麻烦一些。使用\includegraphics需要加载\usepackage{subfigure}。 公式编辑。其实可以使用公式编辑器。MathType 5.0以上,在perferences菜单里的translators选择translate to other languages,然后选择latex。之后,用公式编辑器编辑的公司可以直接用选择和复制放到latex文件当中。 如果公式需要加编号,使用\begin{equation}和\end{equation}就能自动添加编号。不过最好加载 \usepackage{amsmath}。另外,默认公式是居中的,如果需要改成靠左缩进的方式,在\documentclass[fleqn] {firstyearreport}添加这个fleqn选择参数。 参考文献最好使用bibtex管理。管理的软件可以使用Endnote,不过我用的是jabref,一个开源软件,还是很好用的。只要 写上\bibliography{file/reference},这里的file/reference说明参考文献是file /reference.bib文件,所有的参考文献就可以自动加载。关于参考文献的风格,我使用的 是\bibliographystyle{alpha},以作者的第一字母和年代为标号。但是还有很多其他的方式,可以参考这个网站:http://www.cs.stir.ac.uk/~kjt/software/latex/showbst.html 图片格式是一个很烦人的问题。最基本的图片格式是eps,尽管现在pdflatex支持pdf和jpeg,png等等,但是我还是认为eps比较好。eps是矢量图,没有图像失真。用eps转换成的pdf放大多少都没有问题,体积也很小。 但是,支持eps的软件并不多。在windows上,我们最习惯的是Visio画图,但是visio对eps基本上没有支持。网上有很多将visio的图转化成eps的图的方法,但是很多都很麻烦。我现在终于找到了一种比较好的方式。 首先安装一个postscript的虚拟打印机,http://www.adobe.com/support/downloads/detail.jsp?ftpID=1502。然后用visio将图片用postscript打成prn或者ps文件。用CTex自带的GSview打开该文件(没有也没关系,下一个:http://pages.cs.wisc.edu/~ghost/),file菜单中有一个ps to eps,哈哈,自动转换边界,就变成eps文件了,而且是矢量的。 还有一个问题,pdflatex偏偏是不支持eps文件,默认是pdf文件。使用pdflatex时,如果没有pdf文件会报错。有人说使 用\usepackage{epstopdf}可以解决该问题,eps文件会自动在编译时变为pdf文件,但是在windows上的使用结果很糟 糕,eps文件没有自动转换边界,按A4打印,结果很难看。 其实加载\usepackage{epstopdf},就是使用epstopdf命令转换eps文件。但是在windows系统中的 epstopdf命令好像不能自动转换边界,但是linux系统上的epstopdf是好的。所以我建议使用linux系统上的epstopdf命令转 化,是会自动转化边界的。 不过大批的文件一个一个去手动转化还是很麻烦,我就写了一个makefile文件,假设所有的eps文件都在一个文件夹下,那么make all一下,就能自动转化为pdf文件。知道我在说什么吧,呵呵。Makefile的内容如下: clean: eps_file = $(wildcard *.eps) pdf_file = $(eps_file:%.eps=%.pdf) $(pdf_file): %.pdf : %.eps all: $(pdf_file) show: 伪代码。伪代码有时候还是要用的,对于复杂的算法,直接写伪代码有时候更容易懂。关于伪代码有一个包algorithms,需要加 载\usepackage{algorithm}和\usepackage{algorithmic},具体用法可以直接看他的帮助,在下载的压缩包中的 doc目录下。下载路径:http://www.ctan.org/tex-archive/help/Catalogue/entries/algorithms.html 忘了说了,所有Latex相关的文件找不到,或者需要最新版,请查询www.ctan.org. 附录。需要插入附录的话,下面的命令会很有用 \appendix \appendix说明之后的内容为附录,\appendixpage将添加一个专门的附录页,\addappheadtotoc将附录添 加到目录当中,需要加载\usepackage{appendix}。不过,一旦附录开始,将不能转回正文。另一种方式可以使用 \begin{appendices}和\end{appendices}在正文中添加附录,参看http://www.tex.ac.uk/cgi-bin/texfaq2html?label=appendix 关于文档中的引用链接和生成pdf的链接目录,只能使用pdflatex。方法是加载\usepackage{hyperref},所有链接自动生成。 关于所有的latex相关的命令,有一本手册(书)http://tobi.oetiker.ch/lshort/lshort.pdf ,好像有中文的翻译版本 http://net.ytu.edu.cn/share/%D7%CA%C1%CF/lshort-cn.pdf 工具:
一些使用心得:
\centering
\includegraphics[width=0.6\textwidth]{file/vcrouter}
\caption{Internal structure of a VC router}\label{fig:vcrouter}
\end{figure}
\centering \subfigure[A bundled-data channel]{
\includegraphics[width=0.30\textwidth]{file/bundleddata}\label{fig:bundleddata}}
\hspace{0.1\textwidth} \subfigure[The 4-phase bundled-data
protocol]{
\includegraphics[width=0.4\textwidth]{file/4phasebundled}\label{fig:4phasebundled}}
\caption{The 4-phase bundled-data protocol}\label{fig:4pb}
\end{figure}
rm -f *.pdf
epstopdf $<
echo $(pdf_file)
\appendixpage
\addappheadtotoc
8.18.2008
Intel Mobile Processor Compatibility Guide
Intel Mobile Processor Compatibility Guide
Introduction
A few months ago I tried to perform processor upgrades on a relative's Dell Inspiron 1150. The 1150 had a Socket 478 Mobile Celeron that ran hot and performed poorly. After doing some cursory research I thought I knew what I was doing and bought a Socket 479 Pentium M. Needless to say, it didn't fit. So I did a bit more research and found myself mired in the rather confusing world of mobile sockets. And it took me a while to figure things out. Recently, after reading a few threads concerning processor upgrades, I figured I'd make a guide. It'd be fun. It couldn't be that hard.
So this is my first guide on NBR and while it's more of a chart and may or may not be terribly helpful, it should, at the very least make a reasonable reference for those of you interested in upgrading mobile Intel processors.
About This Guide
This guide does NOT list every Intel mobile processor. Processors older than the Pentium 4-M and associated Celerons have been omitted. Some chipsets supporting the Pentium 4-M, Mobile Pentium 4 and associated Celerons may also be missing.
Sockets
Current Intel mobile processors can fit one of four mobile sockets. These are Sockets 478 (N), 479, M and P. Laptops utilizing Sockets 478 and 479 are no longer being produced and laptops utilizing Socket 478 are becoming few and far apart. All four sockets have 478 pins in flip-chip pin grid array and are incompatible with each other.
Processors
This guide lists all Pentium 4-M, Mobile Pentium 4, Pentium M, Core Solo, Core Duo, Core 2 Duo, Mobile Celeron and Celeron M chips. Processors under a particular brand are listed according to core. Each processor entry is followed by its clock speed (in MHz), its L2 cache size (in KB) and its front side bus speed (in MHz). All processors listed under a particular socket are mechanically compatible with that socket.
Chipsets
This guide lists mobile 845, 852, 855, 910, 915, 940, 943, 945, 960 and 965 chipsets. As a rule of thumb, chipset names including a G usually ship with integrated graphics and chipset names including a P always ship with dedicated graphics. Processors listed under a particular brand are followed by compatible chipsets. Each chipset entry is followed by its front side bus speed (in MHz). Not all chipsets listed under a particular brand of processor will be compatible with each and every associated processor.
Compatibility
In order for a particular processor to be compatible with a particular laptop; (1) the processor must be physically compatible with the laptop socket, (2) the laptop chipset must support the processor, (3) the chipset front side bus speed must match the processor front side bus speed, (4) the laptop BIOS must support the process.
This guide does not guarantee compatibility. Laptops are immensely complicated machines and sometimes will not be compatible with a particular processor even if the four aforementioned conditions are met. Sometimes, the opposite will be true. The most accurate way to use this guide may be to find out what WILL NOT work rather than what will work.
Socket 478
Socket 478 supports Pentium 4-M, Mobile Pentium 4, Mobile Pentium 4 HT and associated Celerons based on Northwood and Prescott cores. These chips were produced from 2002 to 2005.
Pentium 4-M
Northwood
Pentium 4-M 1.4 1400 512 400
Pentium 4-M 1.5 1500 512 400
Pentium 4-M 1.6 1600 512 400
Pentium 4-M 1.7 1700 512 400
Pentium 4-M 1.8 1800 512 400
Pentium 4-M 1.9 1900 512 400
Pentium 4-M 2.0 2000 512 400
Pentium 4-M 2.1 2100 512 400
Pentium 4-M 2.2 2200 512 400
Pentium 4-M 2.3 2300 512 400
Pentium 4-M 2.4 2400 512 400
Pentium 4-M 2.5 2500 512 400
Pentium 4-M 2.6 2600 512 400
Chipsets
845MZ 400
845MP 400
Mobile Pentium 4
Northwood
Mobile Pentium 4 2.4 2400 512 533
Mobile Pentium 4 2.66 2667 512 533
Mobile Pentium 4 2.8 2800 512 533
Mobile Pentium 4 3.06 3066 512 533
Mobile Pentium 4 3.2 3200 512 533
Chipsets
852GME 400/533
852PM 400/533
Mobile Pentium 4 HT
Northwood
Mobile Pentium 4 HT 2.66 2667 512 533
Mobile Pentium 4 HT 2.8 2800 512 533
Mobile Pentium 4 HT 3.06 3066 512 533
Mobile Pentium 4 HT 3.2 3200 512 533
Prescott
Mobile Pentium 4 HT 518 2800 1024 533
Mobile Pentium 4 HT 532 3066 1024 533
Mobile Pentium 4 HT 538 3200 1024 533
Mobile Pentium 4 HT 548 3333 1024 533
Mobile Pentium 4 HT 552 3466 1024 533
Chipsets
852GME 400/533
852PM 400/533
Mobile Celeron
Northwood
Mobile Celeron 1.4 1400 256 400
Mobile Celeron 1.5 1500 256 400
Mobile Celeron 1.6 1600 256 400
Mobile Celeron 1.7 1700 256 400
Mobile Celeron 1.8 1800 256 400
Mobile Celeron 2.0 2000 256 400
Mobile Celeron 2.2 2200 256 400
Mobile Celeron 2.4 2400 256 400
Mobile Celeron 2.5 2500 256 400
Chipsets
845MZ 400
845MP 400
852GME 400/533
852GMV 400/533
852GM 400/533
852PM 400/533
Socket 479
Socket 479 supports Pentium M and associated Celerons based on Banias and Dothan cores. These chips were produced from 2003 to 2007.
Pentium M
Banias
Pentium M 1.3 1300 1024 400
Pentium M 1.4 1400 1024 400
Pentium M 1.5 1500 1024 400
Pentium M 1.6 1600 1024 400
Pentium M 1.7 1700 1024 400
Dothan
Pentium M 710 1400 2048 400
Pentium M 715 1500 2048 400
Pentium M 725 1600 2048 400
Pentium M 735 1700 2048 400
Pentium M 745 1800 2048 400
Pentium M 755 2000 2048 400
Pentium M 765 2100 2048 400
Pentium M 730 1600 2048 533
Pentium M 740 1733 2048 533
Pentium M 750 1866 2048 533
Pentium M 760 2000 2048 533
Pentium M 770 2133 2048 533
Pentium M 780 2266 2048 533
Chipsets
855GME 400
855GM 400
855PM 400
915GMS 400
915GM 400/533
915PM 400/533
Celeron M
Banias-512
Celeron M 310 1200 512 400
Celeron M 320 1300 512 400
Celeron M 330 1400 512 400
Celeron M 340 1500 512 400
Dothan-512
Celeron 205 1200 512 400
Dothan-1024
Celeron M 350 1300 1024 400
Celeron M 360 1400 1024 400
Celeron M 370 1500 1024 400
Celeron M 380 1600 1024 400
Celeron M 390 1700 1024 400
Chipsets
855GME 400
855GM 400
855PM 400
910GML 400
915GMS 400
915GM 400/533
915PM 400/533
Socket M
Socket M supports Core Solo, Core Duo, some Core 2 Duo, Pentium Dual-Core and associated Celerons based on Yonah and Merom cores. These chips were produced from 2006 to the present.
Core Solo
Yonah
Core Solo T1350 1866 2048 533
Core Solo T1200 1500 2048 667
Core Solo T1300 1660 2048 667
Core Solo T1400 1833 2048 667
Core Solo T1500 2000 2048 667
Core Solo T1600 2166 2048 667
Chipsets
940GML 533
943GML 533
945GMS 533/667
945GM 533/667
945PM 533/667
Core Duo
Yonah
Core Duo T2050 1600 2048 533
Core Duo T2250 1733 2048 533
Core Duo T2350 1866 2048 533
Core Duo T2450 2000 2048 533
Core Duo T2300 1666 2048 667
Core Duo T2400 1833 2048 667
Core Duo T2500 2000 2048 667
Core Duo T2600 2166 2048 667
Core Duo T2700 2300 2048 667
Chipsets
943GML 533
945GM 533/667
945PM 533/667
Core 2 Duo
Merom-2M
Core 2 Duo T5300 1733 2048 533
Core 2 Duo T5500 1667 2048 667
Core 2 Duo T5600 1833 2048 667
Merom
Core 2 Duo T5200 1600 2048 533
Core 2 Duo T5500 1667 2048 667
Core 2 Duo T5600 1833 2048 667
Core 2 Duo T7200 2000 4096 667
Core 2 Duo T7400 2166 4096 667
Core 2 Duo T7600 2333 4096 667
Chipsets
943GML 533
945GM 533/667
945PM 533/667
Pentium Dual-Core
Yonah
Pentium Dual-Core T2060 1600 1024 533
Pentium Dual-Core T2080 1733 1024 533
Pentium Dual-Core T2130 1866 1024 533
Chipsets
943GML 533
945GM 533/667
945PM 533/667
Celeron M
Yonah-512
Celeron 215 1333 512 533
Yonah-1024
Celeron M 410 1466 1024 533
Celeron M 420 1600 1024 533
Celeron M 430 1733 1024 533
Celeron M 440 1866 1024 533
Celeron M 450 2000 1024 533
Merom-L
Celeron M 520 1600 1024 533
Celeron M 530 1733 1024 533
Chipsets
940GML 533
943GML 533
945GMS 533/667
945GM 533/667
945PM 533/667
Socket P
Socket P supports some Core 2 Duo, Pentium Dual-Core and associated Celerons based on Merom and Penryn cores. These chips were produced from 2007 to the present.
Core 2 Duo
Merom-2M
Core 2 Duo T5250 1500 2048 667
Core 2 Duo T5450 1667 2048 667
Core 2 Duo T5550 1833 2048 667
Core 2 Duo T5750 2000 2048 667
Core 2 Duo T5850 2133 2048 667
Core 2 Duo T5270 1400 2048 800
Core 2 Duo T5470 1600 2048 800
Core 2 Duo T7100 1800 2048 800
Core 2 Duo T7250 2000 2048 800
Merom
Core 2 Duo T7300 2000 4096 800
Core 2 Duo T7500 2200 4096 800
Core 2 Duo T7700 2400 4096 800
Core 2 Duo T7800 2600 4096 800
Penryn-3M
Core 2 Duo T8100 2100 3072 800
Core 2 Duo T8300 2400 3072 800
Penryn
Core 2 Duo T9300 2500 6144 800
Core 2 Duo T9500 2600 6144 800
Chipsets
GM965 533/800
PM965 533/800
Core 2 Extreme
Merom XE
Core 2 Extreme X7800 2600 4096 800
Core 2 Extreme X7900 2800 4096 800
Penryn XE
Core 2 Extreme X9000 2800 6144 800
Pentium Dual-Core
Merom-2M
Pentium Dual-Core T2310 1466 1024 533
Pentium Dual-Core T2330 1600 1024 533
Pentium Dual-Core T2370 1733 1024 533
Chipsets
GL960 533
GM965 533/800
PM965 533/800
Celeron M
Merom-L
Celeron M 530 1733 1024 533
Celeron M 540 1866 1024 533
Celeron M 550 2000 1024 533
Celeron M 560 2133 1024 533
Chipsets
GL960 533
GM965 533/800
PM965 533/800
LV and ULV
Low-voltage and ultra-low-voltage processors are usually soldered to the motherboard and therefore unassociated with a particular socket. You will unlikely be able to remove or replace a low-voltage or ultra-low-voltage processor.
Pentium M
Banias, LV
Pentium M LV 1.1 1100 1024 400
Pentium M LV 1.2 1200 1024 400
Pentium M LV 718 1300 1024 400
Banias, ULV
Pentium M ULV 900 900 1024 400
Pentium M ULV 1.0 1000 1024 400
Pentium M ULV 713 1100 1024 400
Dothan, LV
Pentium M LV 738 1400 2048 400
Pentium M LV 758 1500 2048 400
Pentium M LV 778 1600 2048 400
Dothan, ULV
Pentium M ULV 723 1000 2048 400
Pentium M ULV 733 1100 2048 400
Pentium M ULV 753 1200 2048 400
Pentium M ULV 773 1300 2048 400
Core Solo
Yonah, ULV
Core Solo ULV U1300 1066 2048 533
Core Solo ULV U1400 1200 2048 533
Core Solo ULV U1500 1333 2048 533
Core Duo
Yonah, LV
Core Duo LV L2300 1500 2048 667
Core Duo LV L2400 1666 2048 667
Core Duo LV L2500 1833 2048 667
Yonah, ULV
Core Duo ULV U2400 1066 2048 533
Core Duo ULV U2500 1200 2048 533
Core 2 Solo
Merom-L, ULV
Core 2 Solo ULV U2100 1066 1024 533
Core 2 Solo ULV U2200 1200 1024 533
Core 2 Duo
Merom, LV
Core 2 Duo LV L7200 1333 4096 667
Core 2 Duo LV L7400 1500 4096 667
Core 2 Duo LV L7300 1400 4096 800
Core 2 Duo LV L7500 1600 4096 800
Core 2 Duo LV L7700 1800 4096 800
Merom-2M, ULV
Core 2 Duo ULV U7500 1066 2048 533
Core 2 Duo ULV U7600 1200 2048 533
Core 2 Duo ULV U7700 1333 2048 533
Celeron M
Banias-512, ULV
Celeron M ULV 800 800 512 400
Celeron M ULV 900 900 512 400
Dothan-1024, ULV
Celeron M ULV 383 1000 1024 400
Dothan-512, ULV
Celeron M ULV 353 900 512 400
Celeron M ULV 373 1000 512 400
Yonah-1024, ULV
Celeron M ULV 423 1066 1024 533
Celeron M ULV 443 1200 1024 533
Merom-L, ULV
Celeron M ULV 523 933 1024 533
Postscript
All initial data was gathered from Wikipedia.org and Intel.com, with additional data and corrections provided by NBR members. All comments, questions or concerns are appreciated. Always looking to improve the guide (R10).
Notes on the GL960
08/04/05
As of this update, the GL960 only has official support for Socket P Celerons. Manufacturers, however, have been shipping the GL960 with Socket P Pentium Dual-Cores. The GL960 will certainly work with the following processors:
Celeron M 530 1733 1024 533
Celeron M 540 1866 1024 533
Celeron M 550 2000 1024 533
Celeron M 560 2133 1024 533
Pentium Dual-Core T2310 1466 1024 533
Pentium Dual-Core T2330 1600 1024 533
Pentium Dual-Core T2370 1733 1024 533
As of this update, several board members have reported successful uprades to 667MHz FSB and 800MHz FSB Socket P Core 2 Duos and none have reported unsuccessful upgrades. The GL960 will probably work with the following processors:
Core 2 Duo T5250 1500 2048 667
Core 2 Duo T5450 1667 2048 667
Core 2 Duo T5550 1833 2048 667
Core 2 Duo T5750 2000 2048 667
Core 2 Duo T5850 2133 2048 667
Core 2 Duo T5270 1400 2048 800
Core 2 Duo T5470 1600 2048 800
Core 2 Duo T7100 1800 2048 800
Core 2 Duo T7250 2000 2048 800
Core 2 Duo T7300 2000 4096 800
Core 2 Duo T7500 2200 4096 800
Core 2 Duo T7700 2400 4096 800
Core 2 Duo T7800 2600 4096 800
If you are looking to upgrade a machine with a GL960 chipset, there is a good chance that you can use any of these thirteen processors, though once again, compatibility is not guaranteed.
8.07.2008
国外学术类网免费全文网站
【转载】国外学术类网免费全文网站
1.http://adswww.harvard.edu/
The NASA Astrophysics Data System
-- 世界最大免费全文网站,超过300,000篇全文
主要学科:天体物理学
2.http://intl.highwire.org/
HighWire Press
-- 世界第二大免费全文网站,超过235,812篇全文
主要学科:生物学、医学
3.http://arxiv.org/
arXiv.org
主要学科:物理、数学、非线性科学、计算机科学等。文件格式以PostScript为主,如
没有相应的阅读软件,可以选择生成PDF文件格式。
4.http://www.cogsci.soton.ac.uk/bbs/
Behavioral and Brain Sciences
主要学科:行为科学、脑科学
5.http://www.cdc.gov/
Centers for Disease Control and Prevention (CDC)
主要学科:医学
6.http://cogprints.soton.ac.uk/
CogPrints
主要学科:心理学、神经科学、行为科学、语言学、人工智能、哲学
7.http://www.access.gpo.gov/su_docs/databases.html
GPO Access
美国政府文献
8.http://www.icpsr.umich.edu/index.html
Inter-university Consortium for Political and Social Research (ICPSR)
世界最大的社会科学文献网站
9.http://www.nationalacademies.org/publications/
National Academy Press
美国国家科学院、国家工程院、医学协会等机构报告
10.http://www.cdc.gov/nchs/
National Center for Health Statistics (NCHS)
美国国家卫生统计中心的统计报告
美国国家卫生统计中心的统计报告
11.http://www.ncstrl.org/
NCSTRL
计算机科学研究报告和论文
12.http://promo.net/pg/
Project Gutenberg Electronic Public Library
电子图书,2002前提供10000种全文电子图书
13.http://thomas.loc.gov/
Thomas Legislative Information on the Internet
美国国会图书馆提供的美国国会报告和历史文献
14.http://unesdoc.unesco.org/ulis/
UNESCO
联合国教科文组织提供的文档
15.http://www.usgs.gov/
United States Geological Survey
美国地质考察报告
16.http://www-wds.worldbank.org/
World Development Sources (World Bank)
世界银行报告
17.http://www.delphion.com/boolquery
Delphion
世界各国专利,可看到前十三页全文
18.http://ep.espacenet.com/
电子图书,2002前提供10000种全文电子图书
欧洲专利局,也可查世界专利
7.29.2008
网络爬虫
随着网络技术的发展,互联网已经成为海量信息的载体,随着人们对这些信息进行有效提取以及应用的需求的增加,搜索引擎(Search Engine)应运而生,例如传统的通用搜索引擎AltaVista,Yahoo!和Google等,作为一个辅助人们检索信息的工具成为用户访问万维网 的入口和指南。但是,这些通用性搜索引擎也存在着一定的局限性,如:
1、针对不同需求,不同背景的用户,搜索引擎还不够智能,返回的结果大多包含对用户无用的信息。
2、不能很好地发现和获取图片、数据库、音频/视频多媒体等不同数据。
为了解决上述问题,便产生了定向抓取相关网页资源的聚焦爬虫,与通用爬虫(即大部分搜索引擎所使用的爬虫)相比, 聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。聚焦爬虫是一个自动下载网页的程序,它根 据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。
1 网络爬虫的工作原理
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定 停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根 据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进 行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1) 对抓取目标的描述或定义;
(2) 对网页或数据的分析与过滤;
(3) 对URL的搜索策略。
抓取目标的描述和定义是决定网页分析算法与URL搜索策略如何制订的基础。而网页分析算法和候选URL排序算法是决定搜索引擎所提供的服务形式和爬虫网页抓取行为的关键所在。这两个部分的算法又是紧密相关的。
2 抓取目标描述
现有聚焦爬虫对抓取目标的描述可分为基于目标网页特征、基于目标数据模式和基于领域概念3种。
基于目标网页特征的爬虫所抓取、存储并索引的对象一般为网站或网页。根据种子样本获取方式可分为:
(1) 预先给定的初始抓取种子样本;
(2) 预先给定的网页分类目录和与分类目录对应的种子样本,如Yahoo!分类结构等;
(3) 通过用户行为确定的抓取目标样例,分为:
a) 用户浏览过程中显示标注的抓取样本;
b) 通过用户日志挖掘得到访问模式及相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征,等等。
现有的聚焦爬虫对抓取目标的描述或定义可以分为基于目标网页特征,基于目标数据模式和基于领域概念三种。
基于目标网页特征的爬虫所抓取、存储并索引的对象一般为网站或网页。具体的方法根据种子样本的获取方式可以分为:
(1)预先给定的初始抓取种子样本;
(2)预先给定的网页分类目录和与分类目录对应的种子样本,如Yahoo!分类结构等;
(3)通过用户行为确定的抓取目标样例。其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征,等等。
3 网页搜索策略
网页的抓取策略可以分为深度优先、广度优先和最佳优先三种。深度优先在很多情况下会导致爬虫的陷入(trapped)问题,目前常见的是广度优先和最佳优先方法。
3.1 广度优先搜索策略
广度优先搜索策略是指在抓取过程中,在完成当前层次的搜索后,才进行下一层次的搜索。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页,一般使用 广度优先搜索方法。也有很多研究将广度优先搜索策略应用于聚焦爬虫中。其基本思想是认为与初始URL在一定链接距离内的网页具有主题相关性的概率很大。另 外一种方法是将广度优先搜索与网页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。这些方法的缺点在于,随着抓取网页的增多,大 量的无关网页将被下载并过滤,算法的效率将变低。
3.2 最佳优先搜索策略
最佳优先搜索策略按照一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关性,并选取评价最好的一个或几个URL进行抓取。它只访问经 过网页分析算法预测为“有用”的网页。存在的一个问题是,在爬虫抓取路径上的很多相关网页可能被忽略,因为最佳优先策略是一种局部最优搜索算法。因此需要 将最佳优先结合具体的应用进行改进,以跳出局部最优点。将在第4节中结合网页分析算法作具体的讨论。研究表明,这样的闭环调整可以将无关网页数量降低 30%~90%。
=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=~=
世界上第一个网络爬虫是由麻省理工学院 (MIT)的学生马休.格雷(Matthew Gray)在 1993 年写成的。他给他的程序起了个名字叫“互联网漫游者”("www wanderer")。以后的网络爬虫越写越复杂,但原理是一样的。
我们来看看网络爬虫如何下载整个互联网。假定我们从一家门户网站的首页出发,先下载这个网页,然后通过分析这个网页,可以找到藏在它里面的所有超链接,也 就等于知道了这家门户网站首页所直接连接的全部网页,诸如雅虎邮件、雅虎财经、雅虎新闻等等。我们接下来访问、下载并分析这家门户网站的邮件等网页,又能 找到其他相连的网页。我们让计算机不停地做下去,就能下载整个的互联网。当然,我们也要记载哪个网页下载过了,以免重复。在网络爬虫中,我们使用一个称为 “哈希表”(Hash Table)的列表而不是一个记事本纪录网页是否下载过的信息。
现在的互联网非常巨大,不可能通过一台或几台计算机服务器就能完成下载任务。比如雅虎公司(Google 没有公开公布我们的数目,所以我这里举了雅虎的索引大小为例)宣称他们索引了 200 亿个网页,假如下载一个网页需要一秒钟,下载这 200 亿个网页则需要 634 年。因此,一个商业的网络爬虫需要有成千上万个服务器,并且由快速网络连接起来。如何建立这样复杂的网络系统,如何协调这些服务器的任务,就是网络设计和 程序设计的艺术了。
在Java中,网络爬虫大体需要一下几个方面的知识:
1 多线程的自动HTTP下载。
2 HTML文件的格式解析。
3 把解析后的文件存入数据库。
7.23.2008
SVN tag和branch的选择及应用
在实现上,branch和tag,对于svn都是使用copy实现的,所以他们在默认的权限上和一般的目录没有区别。至于何时用tag,何时用branch,完全由人主观的根据规范和需要来选择,而不是强制的(比如cvs)。
一般情况下,
tag,是用来做一个milestone的,不管是不是release,都是一个可用的版本。这里,应该是只读的。更多的是一个显示用的,给人一个可读(readable)的标记。
branch,是用来做并行开发的,这里的并行是指和trunk进行比较。
比如,3.0开发完成,这个时候要做一个tag,tag_release_3_0,然后基于这个tag做release,比如安装程序等。trunk进入 3.1的开发,但是3.0发现了bug,那么就需要基于tag_release_3_0做一个branch,branch_bugfix_3_0,基于这 个branch进行bugfix,等到bugfix结束,做一个tag,tag_release_3_0_1,然后,根据需要决定 branch_bugfix_3_0是否并入trunk。
对于svn还要注意的一点,就是它是全局版本号,其实这个就是一个tag的标记,所以我们经常可以看到,什么什么release,基于xxx项目的 2xxxx版本。就是这个意思了。但是,它还明确的给出一个tag的概念,就是因为这个更加的可读,毕竟记住tag_release_1_0要比记住一个 很大的版本号容易的多。
Java学习网站
1、java研究组织 (http://www.javaresearch.org/index.jsp)。
该网站有许多文章,涉及java的各个领域和方向。另为还有许多软件和书籍的下载,
使一个java学习的不错的网站,有空去逛逛,会学到许多的东西。
2、灰狐动力(http://www.huihoo.com/)
该站点有许多的开源的项目的介绍和学习,涉及操作系统,数据库等许多方向;有如多的英文的文档,可以提高英文文档的阅读能力。
3、java爱好者(http://www.javafan.net)
该网站是一个不错的网站,有许多的java学习资源,不足自出是文章少。
4、爪哇流氓(http://www.kissjava.com)
在这里你可以找到如多java开发工具的破解文件。对于学习开发工具是比较好的
5、sun中国技术社区(http://gceclub.sun.com.cn/index.html)
这里有有关sun公司在java发展,操作系统等许多的信息和软件的更新;时不时的浏览一下,可以了解一下 java的最新信息
6、IBM developerworks java社区(http://www-128.ibm.com/developerworks/cn/java/index.html)
在这里有许多最权威的专家发表的java学习的各方面文章,对提高java学习时非常有好处的。
7、java中文文章学习(http://www.gbg.cn/)
这里可以阅读到许多的中文文章,对于英文不好的同仁,是不错的选择。
8、中国it认证试验室(http://www.chinaitlab.com/index.htm)
在这里可以学到许多的东西,除了java之外的许多的东西,当然java的东西也不少。
9、J道(http://www.jdon.com/idea.html)
这里可以学到关于j2ee的应用技术,对j2ee有兴趣的朋友,不妨来逛一下
10、javalobby(http://www.javalobby.org/)
这是一个英文网站,闲来没事,上去看看,不但了解java相关信息,还可以提高英文水平,何乐而不为。
11、java导航(http://www.wsjava.com/)
这是一个非常全面的JAVA导航网站。
12、http://www.theserverside.com/home/ (英文)
TheServerSide是一个著名的专门面向Java Server端应用的网站。
13、http://www.javaresearch.org/
Java研究组织,有很多优秀的Java方面的文章和教程,特别是在JDO方面的文章比较丰富。
14、http://www.cnjsp.org/
JSP技术网站,有相当多的Java方面的文章和资源。
15、http://www.jdon.com/
Jdon论坛,是一个个人性质的中文J2EE专业技术论坛,在众多的Java的中文论坛中,
Jdon一个是技术含量非常高,帖子质量非常好的论坛。
16、http://sourceforge.net/
SourgeForge是一个开放源代码软件的大本营,其中也有非常非常丰富的Java的开放源代码
的著名的软件。
17、http://dev2dev.bea.com.cn/index.jsp
BEA的开发者园地,BEA作为最重要的App Server厂商,有很多独到的技术,
在Weblogic上做开发的朋友不容错过。
不断加精中
好了,以上是本人收集的关于java学习的不错的网站,在这写出来和大家分享希望对大家有用处。
7.22.2008
Mysql在XP下设置及常见错误
将Mysql添加到Windows系统服务中:
1.、 安装服务。
在Windows2000下,安装完成后,并没有把MySQL安装成服务,我们必须执行下面的语句把MySQL注册为服务:installdir\mysql\bin\mysqld-nt –-install。
Windows98下没有服务的概念,所以不用安装服务。
2.、 启动服务
在Windows2000下,安装服务后可以启动MySQL服务:net start mysql。
在Windows98下,可以用下面的命令启动服务:c:\mysql\bin\mysqld,服务启动后在后台运行,并没有界面。
3.、 停止服务
在Windows2000下,可以通过下面的命令停止MySQL服务:net stop mysql。
在Windows98下,可以通过下面命令停止服务:C:\> C:\mysql\bin\mysqladmin -u root shutdown
4、 卸载服务
可以通过下面的命令卸载MySQL服务:installdir\mysql\bin\mysqld-nt –-remove。
经过上面的安装就可以使用了,可以把我们系统空的数据库内建到mySQL数据目录即可,缺省数据库目录在installdir\mysql\data。
访问MySQL数据库可以通过dbExpress组件,dbExpress组件是一组高效的数据库访问组件,只要改变连接串,我们就可以直接把数据源连接到MSSQLServer等数据库。
安装与卸载windows系统服务有专门软件,如果需要,mail to me:wangyihust@163.com
删除了原来的mysql4.1系统服务后,下载了一个5.0的non-install版本,将其添加到windows系统服务后,为什么无法启动?-1056错误
1.报错:Can't find messagefile 'F:\Program Files\mysql\share\english\errmsg.sys'
原因:原来的4.1版本安装在F:\Program Files\mysql目录;而现在的5.0版本在F:\database目录
解决方法:在c:\winnt\目录下找到my.ini文件,修改或删除之
2.报错:ready for connections.
Version: '5.0.21-community-nt' socket: '' port: 3306 MySQL Community Edition (GPL)
原因:socket为空,没有配置mysql;或者端口已经占用
解决方法: \mysql\bin目录下运行MySQLInstanceConfig.exe配置mysql实例
如何更改Win2000服务MySQL属性中的可执行文件路径!
开始时在D盘装了MySQL,后来卸载后,格式化D盘,再次安装,路径与原路径不同,不能通过“net start mysql”启动。查看win2000服务中MYsql的属性,可执行文件路径在位于D盘。现在怎么样更改,或者从服务项去掉Mysql?
注册表里HKEY_LOCAL_MECHINE---SYSTEM ---CurrentControlSet里
启动MYSQL服务时出错的几种解决方法
1
安装MYSQL后更改了ROOT的密码后用net startmysql启动时我就遇到了这样的问题.使用以下命令后c:\mysql\bin\mysqladmin-u root -p shutdown再net start mysql就没有这个错误提示了!
*************
2
MySQL的1067错误
Q:我的Mysql碰到了 1067 错误
错误信息为:
A system error has occurred.
System error 1067 has occurred.
The process terminated unexpectedly.
A:在我的机上的解决办法是:
修改%windir%\my.ini,增加
[mysqld]
#设置basedir指向mysql的安装路径
basedir=D:\Program\Tools\mysql
datadir=D:\Program\Tools\mysql\data
*************
3
已经弄好了!!!
好像是这样……
mysql_install_db 脚本只是在初次安装时才需要运行一次,之后就不用再运行了,不知道是不是这么回事.我把mysql.server拷贝至/etc/rc.d/init.d /中,运行chkconfig mysql.server,至此mysql服务器每次开机自动启动,只要设置好PATH,在命令行上输入mysql就一切 搞定!
看来摸索的过程实在是痛苦啊,这已经折磨我好几天了……
*************
4
问:我的Mysql碰到了 1067 错误
错误信息为:
A system error has occurred.
System error 1067 has occurred.
The process terminated unexpectedly.
答:
解决办法:
1.检查你的Mysql目录有没有给系统的System用户权限。
2.删除掉你的 %WINDOWS%/my.ini 文件。
3.检查你的 c:/my.cnf 文件配置是否正确。
*************
5
【☆☆☆ MySql概要说明 ☆☆☆】
MySql 的默认安装目录是c:mysql,安装结束后没有任何提示信息说安装结束,请点Finish按钮之类的话,直接就退出了。如果需要安装到其他目录,建议先 安装到c:mysql,然后再整个目录move到自己希望的地方,例如移动到d:mysql 之后,需要编辑 d:mysqlmy- example.cnf (*.cnf的文件在Windows 2000中会被注册成为 SpeedDial文件,在资源管理器中无法操作,要用命令行来 启动notepad编辑,例如运行notepadd:mysqlmy-example.cnf ,但是这个文件是UNIX系统下的文本文件格式,在 notepad中不能正确换行,可以用write打开编辑,
或者用write打开后保存一次,再用notepad就可以编辑了。)找到 basedir一行,去掉前面的“#”号注释,将后面的路径改为移动后的目录(目录分隔符要用斜线而不是反斜线),然后另存为:c:my.cnf 用服务 方式启动的MySql如果用 net stop mysql 来停止,会得到一条 出错消息,例如:
C:>net stop mysql
MySql 服务正在停止.
系统出错。
系统发生 1067 错误。
进程意外终止。
MySql 服务已成功停止。
这没有关系,MySql确实已经停止了。但是假如不希望看到任何出错消息 的话,可以用以下的命令来停止:
C:>mysqlbinmysqladmin -u root shutdown
如果没有任何提示信息,说明MySql已经成功停止了。
需要说明的是MySql虽然号称安装简单,易于使用,但是这毕竟是基于SQL的数据库管理系统,所以如果不是对SQL十分精通的话恐怕也不能拿它来做什么
**************
6
mysql服务无法启动的解决方法
mysql服务无法启动
我的操作系统是 win xp
无论安装何版本的mysql,在管理工具的服务中启动mysql服务时都会在中途报错
内容为:在 本地计算机 无法启动mysql服务 错误1067:进程意外中止
经过多方求教,得解决方法如下
查找系统(后来验证应该为windows目录)目录下的my.ini文件,编辑内容(如果没有该文件,则新建一个),至少包含basedir,datadir这两个基本的配置。
[mysqld]
# set basedir to installation path, e.g., c:/mysql
# 设置为MYSQL的安装目录
basedir=D:/www/WebServer/MySQL
# set datadir to location of data directory,
# e.g., c:/mysql/data or d:/mydata/data
# 设置为MYSQL的数据目录
datadir=D:/www/WebServer/MySQL/data
另外,要主意
[WinMySQLadmin]
Server=D:/www/WebServer/MySQL/bin/mysqld-nt.exe
user=root
password=xxxxxxxx
#以上是设置WinMySQLadmin的配置
[Client]
user=root
password=xxxxxxxx
hehe~ 解决了
**************
7
刚刚弄好Mysql 『关键字 1067错误』
比较郁闷,竟然没有想到安装个Mysql也会出错,错误代码是1067 安装卸载了好几次,就是不行,而且把一些禁用了的服务都打开了,但是还是不行。最后我是这样解决的:
在C:\windows里找一找my.ini 然后删除 然后再启动winmysqladmin.exe界面配置mysql,保存my.ini就可以了 启动mysql试试 呵呵
***************
8
mysql 错误 1067: 进程意外终止
这 个问题困扰了一个早晨,非常郁闷!以前我在装mysql的时候从来没有遇到过,可是现在庄这个高版本的就有问题了,我换我装过的低版本的还是一样的问题 (最关键的是操作系统都是一样的)。在windows2000的服务里面启动mysql服务可是总是弹出“错误 1067: 进程意外终止”!
我 感觉问题在配置文件,于是就重新写了my.ini,启动还是一样的效果,我在google上查找无果,崩溃状态!就在此时眼前一亮,一位高人的指点是我豁 然开朗,你的ini文件有否放到windows目录下,我从个人目录的windows目录下,将其拷贝到系统windows目录下,启动服 务,ok!!!
我实在是不满足,为什么有不同呢,我的另外一台机子上装的是4.0.18的版本,它的my.ini就是放在用户目录下的 windows目录下的,而且也运行正常,我现在有点迷惘,人往往在解决了问题以后很少去思考,所以我现在有点想放弃的感觉,如果现在不会得到答案我想这 个在去思考解决基本上是不可能了
